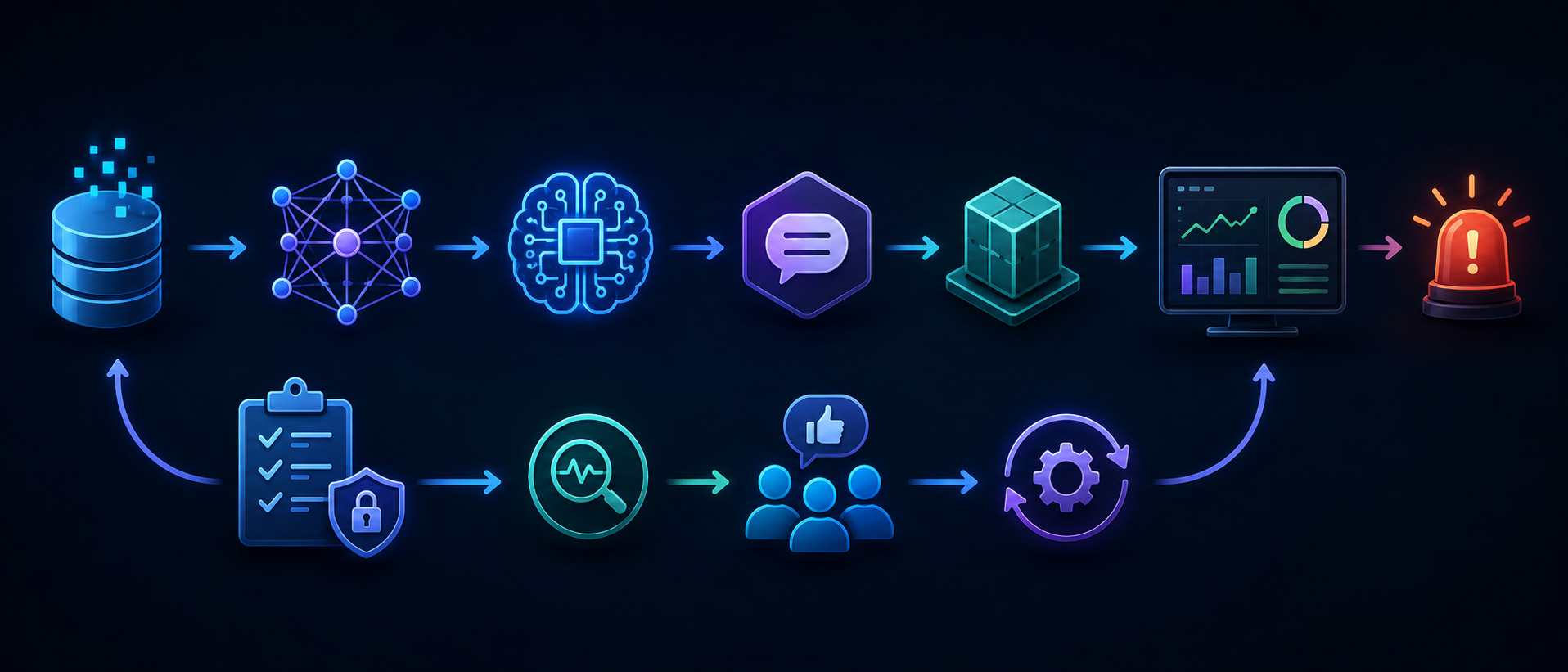
The FM life cycle is just the SDLC with more math and less mercy at 3 a.m.
You have survived canary deployments that took out 40% of prod instead of 5%. You have been paged because someone merged a config change on a Friday. You know exactly what it feels like when your monitoring tells you everything is fine, right up until the moment customers start tweeting.
Now your organization has a foundation model (FM) in production, and I promise you: The on-call playbook you have built over a decade does not cover what happens when your model starts confidently answering customer questions with plausible-sounding nonsense.
Most teams are still treating FM deployment as a data science handoff. Ship the model, write a README, move on. That is the same mistake we made in 2012 when we thought you could just rsync your app to a server and call it a release pipeline. We know how that story ends.
Here is what it actually looks like to run this stuff.
The Base Image Problem (and Why Your Data Team Doesn’t Get It)
Pre-transformer ML was tedious, but at least it was honest. You needed a labeled dataset per use case. Fraud detection, churn prediction, sentiment analysis: Each one a separate model, a separate pipeline, a separate thing to break. The maintenance overhead was brutal, but failure was contained.
FMs break that containment model. One base model, trained on a chunk of the internet, handles everything from code generation to customer support. The appeal is obvious. The operational risk is less so.
Think of pretraining as an extremely expensive compile step. It is where the model learns statistical relationships between concepts. If that compiler runs on low-quality, biased or outdated data, you have baked a hard ceiling into your system. No amount of prompt engineering digs you out of a bad base model. You are optimizing on top of a flawed binary.
If you need to update the model’s knowledge without a full retrain, you use continuous pre-training. Think of it as rebuilding your Docker base image with updated OS packages. Same core logic, refreshed context. It is not cheap, but it is cheaper than discovering your model has no idea what happened in your domain after its training cutoff.
What You Actually Need to Know About the Architecture (Without the PhD)
I am not going to walk you through the math. You do not need it. You need just enough architectural literacy to know where to look when production breaks.
Transformers and the Hallucination at 3 A.M.
Most LLMs you are deploying are transformer-based. The short version: Text becomes vectors, the model predicts what comes next and attention mechanisms let it weigh context across the entire input window. It is elegant until it is not.
When a transformer starts hallucinating, your instinct will be to check the deployment. Wrong move. The model is not broken. The failure mode is almost always a distribution shift: The input looks nothing like the data the model learned on. A financial services model trained on general-purpose data will confidently invent regulatory details. A support bot trained on last year’s product docs will answer questions about features that no longer exist.
Do not debug the container. Debug the input patterns. That is where the failure lives.
Diffusion Models and the Latency Trap
Diffusion models (images, audio, video) are iterative. They start with noise and denoise step by step until you get a coherent output. Every step is a GPU pass. If your generation latency is spiking, scaling horizontally to more H100s is the expensive reflex answer.
Check your sampling steps first. Tuning the inference configuration is almost always faster and cheaper than adding hardware. Understand what you are running before you spend money on compute, you may not need.
Optimization is a FinOps Decision, Not a Science Project
Every CFO who has seen an AI infrastructure bill for the first time has the same expression. You have three levers. They are not interchangeable. Using the wrong one costs time, money and in some cases, model stability.
- Start With Prompt Engineering: It costs nothing in infrastructure, and you will be surprised how far you can get with it. Most teams skip straight to fine-tuning because it feels more technical. That is almost always the wrong call.
- RAG is Your Sweet Spot as an SRE: You pull fresh, relevant data into context at runtime and inject it into the model’s prompt. The model stays current without touching its weights. There is no drift risk on the model itself, your retrieval layer is just another service you already know how to monitor.
- Fine-Tuning is a Last Resort: You are literally modifying the model’s internal weights. You will need a full regression suite. Fix one capability, break three others. The risk profile looks a lot like a major refactor with no rollback plan. Never fine-tune until you have genuinely hit the ceiling with RAG and prompt engineering. The teams that fine-tune too early spend months chasing weight drift they introduced themselves.
The Feedback Loop is the Architecture
Here is what makes AI systems genuinely different from the services you have operated before: They fail without throwing a 500.
Your load balancer shows green. Your error rate is nominal. Response latency looks fine, and somewhere, your model is telling users things that are subtly, confidently wrong. You will not find out from your existing dashboards. You will find out when a customer escalates or when someone screenshots a bad response on LinkedIn.
You need a separate observability layer. Tools like LangSmith or Arize exist specifically because your existing APM stack was not built for this failure mode. Call them optional and you are not running a life cycle: You are hoping for the best with expensive compute.
What you need to monitor:
- Output Drift: Is the distribution of model responses shifting over time, even when inputs look stable?
- Input Anomalies: Are users querying patterns that fall outside the training distribution?
- User Feedback Signals: Thumbs down, correction requests and abandonment patterns are your real-world ground truth.
- Latency Per Component: Your retrieval layer, your model call and your post-processing should be metered separately.
If you are not collecting that signal and feeding it back into your next tuning cycle, you are not running a life cycle. The FM is just drifting and you will not know until the drift is customer-visible.
The Operational Reality
The FM life cycle is the SDLC with more math and more ways to fail silently. The engineers who ship production AI systems, which actually hold up, are not the ones who read the most research papers. They are the ones who treated the model like a service from day one: With runbooks, with observability, with a clear escalation path when outputs degrade.
Everything you already know about operating distributed systems applies here. The failure modes are just newer and quieter.
Treat the FM like any other critical dependency. Own the inputs, monitor the outputs and for the sake of your on-call rotation, do not fine-tune until you have exhausted every cheaper option first.