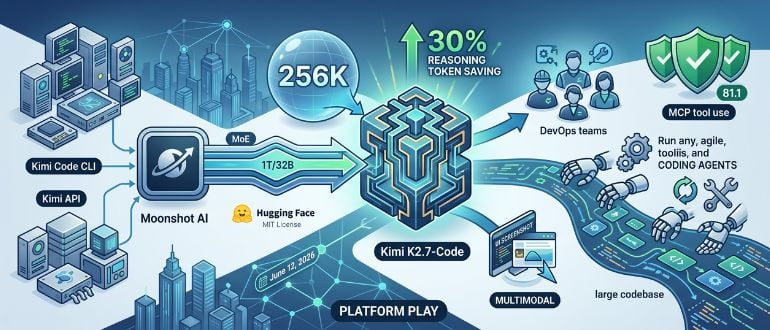

Moonshot AI shipped Kimi K2.7-Code on June 12, 2026 — the fifth major release in the Kimi series in under a year, and arguably the most developer-friendly yet. The model is open-source, available on Hugging Face under a Modified MIT license, and accessible via the Kimi API and the company’s Kimi Code CLI.
The headline claim: a 21.8% improvement on Moonshot’s own Kimi Code Bench v2 over its predecessor, K2.6. But the story that matters more for DevOps teams is efficiency, not just capability.
Fewer Tokens, Less Waste
Moonshot says K2.7-Code cuts reasoning token usage by 30% compared to K2.6. In practical terms, that means developers consume fewer compute resources while getting better results. For teams running coding agents at scale, that’s a meaningful cost reduction — not just a benchmark number.
The model uses a Mixture-of-Experts (MoE) architecture with 1 trillion total parameters but only 32 billion active per token, paired with a 256K-token context window. That combination lets it handle large codebases without activating the full parameter count on every call.
One behavior worth noting: K2.7-Code forces thinking mode on, and you can’t turn it off. The model always reasons before answering. That’s a deliberate design choice, and it affects how you structure workflows and budget token spend.
Benchmark Gains — With Caveats
Moonshot reports strong numbers across several of its internal benchmarks: +21.8% on Kimi Code Bench v2, +11.0% on Program Bench, and +31.5% on MLS Bench Lite versus K2.6.
It’s worth being clear about what those numbers represent. Every benchmark published for K2.7 so far is a Moonshot proprietary benchmark. As of the release date, there were no independent third-party results on standard public suites — SWE-bench Verified, LiveCodeBench, or GPQA Diamond. Treat the scores as vendor-reported and directional, not independently verified.
That doesn’t make the numbers meaningless. It means teams should test the model against their own actual workloads before drawing conclusions.
Built for Agentic Workflows
MCP tool-use is a notable strength. K2.7-Code scored 81.1 on MCP Mark Verified, a suite that tests correct tool invocation through the Model Context Protocol — covering CI checks, ticket updates, and file edits in a single loop.
The model also supports multimodal input, including image and video, which helps with UI screenshots, layout requirements, and interaction debugging. That’s a practical advantage for full-stack development and debugging sessions where visuals are part of the workflow.
The Efficiency Argument Has a Shelf Life
Mitch Ashley, VP and practice lead for software lifecycle engineering and AI-native software engineering at The Futurum Group, puts the token efficiency story in a broader context — and adds a note of caution.
“Token efficiency is a transitory challenge in agentic coding,” Ashley said. “Gains like Moonshot’s claims get absorbed into the base capability of tools and models across release cycles, and inference economics is a problem the market solves structurally. The durable opportunity is inference efficiency delivered as a governable constraint inside an AI harness, where teams operate with token budgets applied at runtime. Vendors building this layer hold a stronger position. Selling a release’s efficiency gain is shipping a feature that the next model erases.”
That’s a useful frame for evaluating K2.7-Code. The 30% token reduction matters today. Whether it matters in six months depends on how fast the rest of the field moves — and how Moonshot builds around the model.
Platform Play, Not Just a Model Drop
The release pairs with Kimi Code, Moonshot’s terminal-first coding agent, with membership plans starting at $19/month — making this as much a platform story as a model story. Moonshot is running the same model-plus-subscription playbook we’ve seen from Anthropic with Claude Code and others.
API pricing sits at $0.95 per million input tokens and $4.00 per million output tokens. Weights are on Hugging Face, and Moonshot says K2.6 deployment patterns can be reused with vLLM, SGLang, or KTransformers.
That last point matters for teams already running K2.6 in production. The migration path is designed to be straightforward — swap the model ID, keep the existing infrastructure.
What This Means for DevOps Teams
The Kimi K2 series has moved fast. Five major releases in under a year signal that Moonshot is iterating aggressively and targeting the developer tooling market directly. K2.7-Code is positioned squarely at long-horizon agentic tasks: Multi-step code generation, CI/CD integration, and large-context codebase analysis.
Ashley’s point about governable constraints is worth sitting with. The teams best positioned to benefit from models like K2.7-Code aren’t just those who adopt them fastest — they’re the ones building runtime controls around token usage, so efficiency gains become predictable operational levers rather than one-release windfalls.
For now, the open-weight release makes evaluation accessible without a large API commitment. Test it against real workloads, measure cost per accepted change, and watch whether the third-party benchmark numbers — when they arrive — support what Moonshot is claiming.