When GitHub’s Copilot Coding Agent (CCA) first became available in May 2025, the promise of cloud-based AI coding agents was generating enormous excitement, and equal skepticism. So we began an experiment, and like many experiments in software engineering, it started with a simple question: could a cloud-based AI coding agent meaningfully contribute to one of the most complex, most scrutinized, and most critical open source codebases in the world?
The dotnet/runtime repository is not a typical codebase. It’s the beating heart of .NET, containing the .NET runtime (including the garbage collector, the JIT compiler, the AOT toolchain) and the hundreds of libraries that form the core of .NET. It spans millions of lines of code across C#, C++, assembly, and a smattering of other languages. It runs on Windows, Linux, macOS, iOS, Android, and WebAssembly. It powers everything from trillion-dollar financial systems to games on your phone, and it’s the lifeblood of the vast majority of Microsoft’s own services. .NET has 7+ million monthly active developers, has had hundreds of thousands of pull requests merged into it from thousands of contributors (across all its constituent repos, with dotnet/runtime at the base), and is consistently in the top 5 of the CNCF highest velocity open source projects on GitHub. If something breaks in dotnet/runtime, millions of developers and customers feel it, viscerally. At the same time, we’re constantly trying to evolve, optimize, and expand the capabilities of .NET, with ever increasing pressures on our core maintainers and ever increasing responsibilities competing for priority. .NET ships annually, with servicing monthly, and developers expect every release to be high quality, chock full of performance improvements and new features to power their businesses.
So with dotnet/runtime, the question wasn’t if we should try CCA, but how we could use it responsibly in a codebase where mistakes can have outsized consequences. “Responsibly” is critical. The .NET team has full ownership for everything we ship. We’re not “handing over” development of .NET to AI; rather, we’re experienced engineers adding a new tool to our workflow. Our standards have not and will not change. Rigor, correctness, and fundamentals are at the heart of everything we do. When we use AI to write code, it’s in service of that goal.
Ten months later, with 878 CCA pull requests in dotnet/runtime alone (535 merged, representing over 95,000 lines of code added and 31,000 lines removed), we have enough data to share what we’ve learned. This is not a cautionary tale of AI gone wrong nor is it a triumphant declaration of AI supremacy. It’s a practical account of human-AI collaboration, of learning what works and what doesn’t, and of the iterative process of teaching AI to contribute to a codebase that took decades of human expertise to build. Let’s start with overall data.
The Numbers at a Glance
This post focuses primarily on dotnet/runtime, which has been a main proving ground for CCA experimentation within .NET. As arguably the most complex and demanding codebase in the .NET ecosystem, it provides a rigorous test for AI-assisted development. The numbers below reflect our current experience there, from May 19, 2025 (when CCA launched) through March 22, 2026 (when I gathered the list of PRs for this post):
| Category | PRs | Merged | Closed | Open | Success Rate |
|---|---|---|---|---|---|
| Human (Microsoft) | 3,082 (50%) | 2,556 | 377 | 149 | 87.1% |
| Human (Community) | 1,411 (23%) | 1,029 | 262 | 120 | 79.7% |
| CCA | 878 (14%) | 535 | 253 | 90 | 67.9% |
| Bot (e.g. dependabot) | 810 (13%) | 666 | 109 | 35 | 85.9% |
| Total | 6,181 | 4,786 | 1,001 | 394 | 82.7% |
Every CCA PR was created at the explicit request of a human with maintainer rights to the repository; CCA cannot open PRs on its own. dotnet/runtime is an open-source project with significant community contributions, and the table above reflects the full PR population. “Microsoft” vs “Community” is determined by users listing Microsoft/MSFT in their public GitHub profile, which likely undercounts Microsoft contributors slightly. “Bot” includes automated PRs from dependency update bots like dotnet-maestro and dependabot. “Success rate” is calculated as merged / (merged + closed), excluding PRs that are still open.
CCA PRs represented 22.2% of all Microsoft-originated PRs by volume (878 out of 3,960 Microsoft + CCA PRs). This measures PR count, not engineering effort; CCA PRs tend to be more bounded in scope than the average human PR, so this overstates CCA’s share of total work. CCA’s 67.9% success rate is also lower than the 87.1% for Microsoft human PRs. However, those comparisons miss crucial context we’ll explore throughout this post: CCA PRs and human PRs are fundamentally different populations facing different selection pressures.
NOTE: This post is grounded in concrete data drawn directly from GitHub (collected with the help of Copilot CLI): PR counts, merge rates, commit histories, review comments, timing, etc. However, these metrics are subject to inherent biases and limitations. CCA PRs are not randomly sampled; they reflect deliberate choices about which tasks to assign to an AI agent, and those choices evolved over the ten months covered here. Success rates depend on what we chose to attempt, not just how well CCA performed. Comparisons between CCA and human PRs are between fundamentally different populations: humans self-select complex, judgment-heavy work while CCA is assigned more bounded tasks. We also note that 90 CCA PRs remain open and are excluded from success rate calculations. The data should be taken directionally, as strong evidence of trends and patterns, rather than as precise benchmarks of AI capability. Where sample sizes are small or methodological caveats apply, we note them.
One quality signal we can measure directly is the revert rate: how often a merged PR is subsequently reverted. Of the 535 merged CCA PRs, 3 were reverted (0.6%). For comparison, 33 of 4,251 non-CCA merged PRs were reverted (0.8%) during the same period. The sample sizes are small enough that the difference is not statistically meaningful, but at minimum, the data shows no red flags. (This analysis identifies reverts by searching for merged PRs with “revert” in the title that references another PR number or title; it may slightly undercount if reverts were accomplished through other means.)
This post focuses primarily on PR throughput metrics (volume, merge rate, time-to-merge, and review/iteration patterns). It does not attempt to comprehensively quantify all downstream quality outcomes, though the revert data above provides one concrete quality signal. It also does not analyze the compute cost of CCA usage or the CI resources consumed by CCA PRs (including failed runs that required iteration). These are real costs, and organizations adopting cloud AI agents like CCA should factor them into their evaluation alongside the productivity benefits described here.
Beyond CCA, we’ve also enabled Copilot Code Review (CCR). Every pull request, whether authored by a member of the .NET team, by CCA, or by an external contributor, automatically receives AI-powered code review feedback. This means every PR that flows through the repository involves AI, not just the ones AI authored. The combination of AI authoring and AI reviewing has become a default workflow. This use of CCA is also separate from any use of AI employed locally by developers, on the .NET team or otherwise, as part of creating PRs; anecdotally from conversations with my teammates, it’s now a significant minority of PRs that don’t involve significant AI as part of design, investigation, and/or coding. As an example, as I write this paragraph, this is my terminal:

(The first tab is copilot reviewing this post looking for various things I asked it to update. The second is rewriting a math component in the .NET core libraries to optimize performance. The third is investigating and fixing a failure in a PR to the modelcontextprotocol repo (that CCA contributed). The fourth is tweaking a terminal UI. And the fifth is updating an IChatClient implementation with new features available in the latest Microsoft.Extensions.AI.Abstractions build.)
Comparison Repositories
To provide context and contrast, I’ve also gathered data from several other of our .NET repositories (ones maintained by the .NET team) where CCA has been used. These aren’t the only places we’ve deployed CCA (it’s been used in another 60 dotnet/* repos), but they offer useful comparisons with dotnet/runtime due to their varying characteristics. These numbers are for the exact same time period, from May 19, 2025 through March 22, 2026:
| Repository | Total PRs | CCA PRs | Merged CCA | Closed CCA | Open CCA | CCA Success Rate | Why It’s Interesting for Comparison |
|---|---|---|---|---|---|---|---|
| microsoft/aspire | 3527 | 1130 | 717 | 390 | 23 | 64.8% | Greenfield cloud-native stack created in fall 2023; the team has been an early and aggressive adopter of CCA. |
| dotnet/roslyn | 2784 | 263 | 165 | 56 | 42 | 74.7% | The C# and Visual Basic compilers and language services; deep domain complexity with decades of history, comparable in maturity to runtime. |
| dotnet/aspnetcore | 1804 | 254 | 151 | 61 | 42 | 71.2% | Large, mature codebase with web-focused domain; tests whether CCA handles framework-level complexity. |
| dotnet/efcore | 1136 | 129 | 83 | 37 | 9 | 69.2% | Highly specialized query translation domain; tests CCA’s ability to handle deep domain expertise requirements. |
| dotnet/extensions | 569 | 127 | 98 | 25 | 4 | 79.7% | Contains our AI-focused libraries (Microsoft.Extensions.AI); newer codebase with modern patterns. |
| modelcontextprotocol/csharp-sdk | 528 | 182 | 136 | 40 | 6 | 77.3% | Greenfield project started in spring 2025; shows CCA performance without legacy burden or historical conventions. |
These comparison repositories help us understand which factors influence CCA success: codebase age, domain complexity, architectural patterns, and the presence of legacy constraints.
Across all seven repositories, we’ve seen 2,963 CCA pull requests with 1,885 merged (68.6% success rate), representing ~392,000 lines added and ~121,000 lines deleted, for a net contribution of roughly 271,000 lines of code.
These repos vary in size and complexity. Enumerating tracked source files (using git ls-files), classifying text vs. binary, and counting lines and tokens (tiktoken o200k_base tokenizer) reveals these numbers to help calibrate:
| Repository | Files | Text Files | Total Text Size | Total Lines | Total Tokens |
|---|---|---|---|---|---|
| dotnet/runtime | 57,194 | 57,005 | ~620.0 MB | 14,159,378 | 187,393,758 |
| dotnet/roslyn | 20,620 | 20,317 | ~375.1 MB | 9,508,662 | 85,964,140 |
| dotnet/aspnetcore | 16,661 | 16,530 | ~162.3 MB | 2,664,610 | 49,002,522 |
| microsoft/aspire | 8,802 | 8,706 | ~108.2 MB | 2,331,915 | 25,958,731 |
| dotnet/efcore | 6,114 | 6,108 | ~81.8 MB | 1,814,334 | 18,978,960 |
| dotnet/extensions | 3,565 | 3,548 | ~23.0 MB | 543,383 | 5,879,188 |
| modelcontextprotocol/csharp-sdk | 735 | 732 | ~4.1 MB | 105,587 | 887,356 |
Change Size Distribution
How big are these CCA PRs? The distribution in dotnet/runtime shows CCA handling changes across a wide range of sizes:
| Lines Changed | PRs | % |
|---|---|---|
| 0 | 59 | 6.7% |
| 1-10 | 170 | 19.4% |
| 11-50 | 222 | 25.3% |
| 51-100 | 120 | 13.7% |
| 101-500 | 215 | 24.5% |
| 501-1,000 | 51 | 5.8% |
| 1,001-5,000 | 32 | 3.6% |
| 5,000+ | 9 | 1.0% |
The 59 zero-line PRs (6.7%) are cases where CCA was invoked but didn’t produce a change, typically either tasks abandoned before the agent began coding (where the developer changed their mind for some reason) or where CCA ended up not making any changes because the issue was already fully addressed. Of the remaining PRs, nearly half (48%) are under 50 lines, such as targeted bug fixes. But over a quarter (26%) are in the 101-500 line range, representing substantial features or refactorings. The handful of 5,000+ line PRs include major refactorings or upgrades, like updating support from Unicode 16.0 to Unicode 17.0 (which entailed CCA writing and merging tools to automate the update, programmatically updating the relevant data files, discovering and running code generators, and more tactical updates such as updating regex’s recognized named character ranges) and comprehensive test coverage additions.
Interestingly, size correlates with success in a non-obvious way:
| Lines Changed | Decided PRs | Success Rate |
|---|---|---|
| 0 | 56 | 0.0% |
| 1-10 | 160 | 80.0% |
| 11-50 | 195 | 76.9% |
| 51-100 | 104 | 75.0% |
| 101-500 | 197 | 64.0% |
| 501-1,000 | 44 | 68.2% |
| 1,001+ | 32 | 71.9% |
The sweet spot is 1-50 lines at 76-80%. Success drops in the 101-500 range (64%), where tasks are large enough to involve multiple interacting components but not so large that they tend to be well-scoped refactorings. The largest PRs (1,001+ lines) rebound to 72%, likely because these tend to be carefully scoped mechanical tasks (like code generation updates or comprehensive test additions) that play to CCA’s strengths. The lesson is that task scope matters more than size: a well-scoped task that produces 50 lines succeeds more reliably than a vague one that produces 200.
Where do all those lines go? Analyzing the file-level data for all 535 merged CCA PRs, 65.7% of lines added were test code (files in test directories), 29.6% were production code, and 4.7% were other files (documentation, project files, etc.). For comparison, a random sample of 500 merged human PRs shows a similar but less pronounced pattern: 49.9% test code, 38.5% production, 11.6% other. The high test percentage isn’t unique to CCA; it reflects the reality that in today’s production codebases, changes generally require as much or more test code than production code. That said, CCA’s 66% test ratio is notably higher than humans’ 50%, consistent with the fact that pure testing tasks are among CCA’s strongest categories and that CCA is disproportionately assigned test-writing work. 56% of all merged CCA PRs touched at least one test file, compared to 38% of human PRs.
The Trajectory
What’s most encouraging is how our success rate in dotnet/runtime has climbed over time:
| Month | PRs | Success Rate | Cumulative Success |
|---|---|---|---|
| May-25 | 24 | 41.7% | 41.7% |
| Jun-25 | 13 | 69.2% | 51.4% |
| Jul-25 | 23 | 69.6% | 58.3% |
| Aug-25 | 36 | 60.0% | 58.9% |
| Sep-25 | 16 | 62.5% | 59.5% |
| Oct-25 | 86 | 58.8% | 59.2% |
| Nov-25 | 75 | 69.0% | 61.8% |
| Dec-25 | 87 | 72.4% | 64.4% |
| Jan-26 | 182 | 71.2% | 66.6% |
| Feb-26 | 196 | 69.7% | 67.4% |
| Mar-26* | 140 | 72.1% | 67.9% |
From 41.7% in our first month to holding steady at ~71% across the most recent quarter. (Early months have small sample sizes, e.g. June 2025 had only 13 PRs, so individual monthly rates should be taken directionally; the cumulative column provides a more stable signal. March 2026 only covers through the 22nd, and 54 of those PRs are still open, so that rate is preliminary.) That’s a story of learning: learning what tasks to assign, learning how to write instructions, learning how to iterate with an AI pair programmer. To understand what that learning curve actually looks like in practice, it helps to zoom in on a few specific experiments along the way.
Tackling the Backlog (and Beyond)
One of CCA’s most tangible impacts is accelerating work that was waiting for someone with time to address it. Of the 464 CCA PRs in dotnet/runtime that link to a source issue, the age of those issues at the time CCA was assigned tells a striking story:
| Issue Age | PRs | % |
|---|---|---|
| Same day | 180 | 38.8% |
| 1-7 days | 42 | 9.1% |
| 1-4 weeks | 31 | 6.7% |
| 1-3 months | 35 | 7.5% |
| 3-12 months | 53 | 11.4% |
| 1-2 years | 30 | 6.5% |
| 2+ years | 93 | 20.0% |
The median issue age is just 11 days, but the average is 382 days (12.6 months), pulled up by a long tail of old issues. 20% of the issues CCA tackled were over two years old, with some dating back as far as 9 years, predating the creation of the dotnet/runtime repository itself (they were migrated from the old coreclr/corefx repos). These are issues that area owners agreed should be fixed, but that never rose to the top of anyone’s priority list. CCA doesn’t have competing priorities; it just needs to be pointed at a problem.
The 39% same-day bucket has two sources: sometimes we create well-scoped issues specifically designed for CCA, filing and assigning within minutes; other times, we triage incoming community-filed issues directly to CCA on the day they arrive. 31% of same-day issues were filed by external contributors, with a median triage-to-CCA time of just 2.7 hours. In the fastest case, a community-reported source generator bug was assigned to CCA under two minutes after being filed. CCA is becoming part of how we respond to incoming reports, not just a tool for pre-planned work. The issues in the 2+ year bucket, by contrast, represent genuine backlog acceleration, work that likely would not have been done for months or years otherwise.
The Birthday Party Experiment
An inflection point in our CCA journey came on a Saturday in October. I was at a birthday party with one of my kids, and while the youngins were off playing, I found myself scrolling through our backlog of dotnet/runtime issues on my phone. Many were tagged “help wanted”, issues that were well-understood but waiting for someone with time to tackle them.
I started assigning issues to Copilot. Not randomly, but thoughtfully: skimming each issue, assessing whether the problem was clear enough, whether the fix was likely within what I understood CCA’s capabilities to be (with Claude Sonnet 4.0 or 4.5 at the time), whether the scope was manageable. Over the course of an hour, I assigned more than 20 issues covering a range of areas.
By evening, I had reviewed 22 pull requests, most of which were reasonable attempts at solving real problems. Some were excellent. Some needed iteration. A few revealed that we shouldn’t make the change at all, which is itself a valuable outcome.
Let me walk through a few representative examples from that day:
The Thread Safety Fix (PR #120619)
The issue described a thread safety problem in System.Text.Json‘s JsonObject.InitializeDictionary that was causing intermittent GetPath failures. I had a hypothesis about the problem and roughly what the fix should look like, so I included that in my prompt when assigning the issue.
Copilot validated my hypothesis, implemented the fix, and added a regression test. The entire review took about 10 minutes, mostly spent on two minor cleanup suggestions. The fix was correct, the test was appropriate, and it merged cleanly.
This is CCA at its best: a well-defined bug with a clear fix that just needs someone (or something) to do the mechanical work of implementing and testing it.
The Intentionally Closed PR (PR #120638)
Sometimes the most valuable outcome of a PR is deciding not to make the change. I assigned an issue about regex quantifiers on anchors (like ^* or $+) where the issue was proposing that this syntax that was currently parsing successfully should instead be rejected as invalid.
Copilot dutifully implemented the change, modifying the parser and, importantly, updating tests. It did a good job, finding exactly the right places to make the changes and making clean, minimal edits to the product source. But reviewing those test changes revealed something important: our existing behavior was intentional. The tests Copilot had to modify to get the tests to pass weren’t bugs, they were documenting deliberate design decisions.
I closed the PR and the corresponding issue. Was this a “failure”? No. Copilot had essentially done the investigative work of determining that the issue shouldn’t be fixed. That’s worth something, several hours of my time had I done it manually.
The Debugging Win (PR #120622)
This one surprised me. The issue involved our NonBacktracking regex engine and empty capture groups with newlines, a subtle bug in a part of the codebase I’m less familiar with. Debugging this manually would have meant stepping through unfamiliar code, understanding the state machine, identifying where the logic diverged. Hours, maybe a day.
Instead, Copilot found the problem and submitted a one-line fix plus tests. Five minutes to review. The fix was trivial, and obvious in hindsight once the source of the problem was found and documented, but finding it was the hard part, and CCA handled that entirely.
The Struggle with BCrypt (PR #120633)
Not everything went smoothly. An issue about using Windows BCrypt for our internal Sha1ForNonSecretPurposes function turned into a 20+ commit odyssey. Copilot’s initial approach produced a mess of #if conditionals. It took multiple rounds of feedback to get it to split the code into platform-specific files, exacerbated by its inability to test the changes on Windows at the time. And it resulted in a native binary size increase for NativeAOT that required more detailed investigation.
This PR was eventually closed. But it taught us something important: CCA struggles with problems that require architectural judgment… choosing the right API shape based on real-world usage patterns, anticipating ripple effects across platforms and build configurations, and understanding the downstream implications of design decisions like interop patterns on binary size. These are skills that come from deep familiarity with a codebase’s conventions and history.
By the end of that Saturday, I had a rough mental model: CCA is excellent at implementing well-specified changes, very good at investigating issues, and relatively poor at architecting solutions, especially in large codebases that require broad understanding. That model has held up well over the following months.
The Redmond Flight Experiment
If the Saturday birthday party demonstrated CCA’s potential for tackling a wide variety of problems, the Redmond flight experiment a few months later demonstrated something different: the sheer throughput that becomes possible when you can work from anywhere with nothing but a phone, and the ramifications of that.
On January 6th, 2026, I boarded a cross-country flight to Redmond, WA. No laptop (or, rather, no ability to charge my power-hungry laptop), just my phone and a movie to watch. But between scenes (and perhaps during a few slow stretches of plot), I found myself scrolling through our issue backlog, assigning issues to Copilot, and kicking off PRs, as well as thinking through some desired performance optimizations and refactorings and submitting tasks via the agent pane.
By the time I landed, I’d opened nine pull requests spanning bug fixes, test coverage increases, performance optimizations, and even experimental data structure work. From a phone. At 35,000 feet. Before CCA, opening nine meaningful PRs during travel wouldn’t have been realistic. Even with a laptop, implementing code changes, writing tests, running local verification, all from an airplane seat, would have been a stretch. From a phone? Not possible.
But with CCA, my job was different. I wasn’t writing code. I was identifying work, scoping problems, and giving direction. The agent did the implementation. Here’s what emerged:
| PR | Title | Status | Scope |
|---|---|---|---|
| #122944 | Fix integer overflow in BufferedStream for large buffers | Merged | Bug fix, +25/-1 |
| #122945 | Add regression tests for TarReader after DataStream disposal | Merged | +226 lines of tests |
| #122947 | Optimize Directory.GetFiles by passing safe patterns to NtQueryDirectoryFile | Merged | Performance optimization, +109/-20 |
| #122950 | Support constructors with byref parameters (in/ref/out) in System.Text.Json | Merged | Feature / bug fix, +8,359/-39 |
| #122951 | Fix baggage encoding by using EscapeDataString instead of WebUtility.UrlEncode | Closed | Encoding fix, +66/-8 |
| #122952 | Optimize HashSet.UnionWith to copy data from another HashSet when empty | Merged | Performance, +52 |
| #122953 | Remove NET9_0_OR_GREATER and NET10_0_OR_GREATER preprocessor constants | Merged | 112 files, +316/-2404 |
| #122956 | Partial Chase-Lev work-stealing deque implementation for ConcurrentBag | Closed | Experimental, +155/-267 |
| #122959 | Port alternation switch optimization from source generator to RegexCompiler | Merged | Performance optimization, complex IL emit, +306/-39 |
Consider PR #122953: removing obsolete preprocessor constants. The repo no longer builds for .NET Core versions older than .NET 10 (but still builds some packages that multitarget to .NET Framework and .NET Standard), so constants like NET9_0_OR_GREATER and NET10_0_OR_GREATER are now always true and, thus, unnecessary clutter. This is a straightforward cleanup, but it touched 112 files across System.Private.CoreLib, Microsoft.Extensions.*, System.Collections.Immutable, System.Text.Json, cryptography libraries, and dozens of test files. It’s also more than just a search/replace, as now unreachable code should be deleted. From my phone, I typed a prompt explaining the goal and the strategy (e.g. replace with #if NET for multi-targeted files, and remove conditionals entirely for .NET Core-only files). CCA analyzed the codebase, applied the correct transformation to each file based on its context, and produced a PR. Could I have done this manually? Sure, in a couple of hours of tedious searching and manual deletion with a laptop. From my phone? Not a chance.
Or consider PR #122959: porting an optimization from the regex source generator to the regex compiler. This involved understanding how the C# compiler lowers switch statements to IL, applying the same heuristic with System.Reflection.Emit, and handling edge cases around atomic alternations. The PR adds 306 lines of complicated IL opcode emission. CCA wrote it; I reviewed it from the ground after landing.
PR #122947 didn’t even start with an issue assignment. I had a conversation with Copilot in “ask mode” on GitHub, sharing the problem statement and going back-and-forth brainstorming possible optimization approaches. When we converged on a viable approach, I asked it to implement. The PR emerged from that collaborative design session, conducted entirely via chat on my phone while waiting to take off.
Seven of the nine PRs merged and two were closed (one because review determined the change wasn’t the right approach and that the underlying issue should be closed as well, and one because the data structure being experimented with was incompatible with the scenario, an issue actually highlighted in the PR description by CCA where it warned against merging).
The practical upshot of this story? CCA changes where and when serious software engineering can happen. The constraint isn’t typing speed or screen real estate: it’s knowledge, judgment, and the ability to articulate what needs to be done. Waiting in an airport? Provide feedback on changes that should be made. Commuting on a train? Trigger a PR. The marginal cost of starting work drops significantly when “starting work” means typing or speaking a direction rather than switching contexts and setting up a development environment.
That highlights a dark side to this superpower, however. I opened nine PRs, some quite complicated, in the span of a few hours. Those PRs need review. Detailed, careful review, the kind that takes at least 30 to 60 minutes per PR for changes of this complexity. That means I quite quickly created 5 to 9 hours of review work, spread across team members who have their own responsibilities and demands for their time. A week later, three of those PRs were still open. Not because they were bad, but because in part reviewers hadn’t gotten to them yet. And that was with me actively pinging people, nudging the PRs forward. The bottleneck has moved. AI changes the economics of code production. One person with good judgment and a phone can generate PRs faster than a team can review them. This creates asymmetric pressure: the person triggering CCA work feels productive (“nine PRs!!”), while reviewers feel overwhelmed (“nine PRs??”).
For a repository like dotnet/runtime, where reliability is paramount, where changes affect millions of developers and consumers, where our ship cycle demands confidence, we cannot compromise on review quality, on expert and experienced eyes validating the changes (at least the spirit of them if not the dotting of the is). But we also can’t ignore the bottleneck. If PR generation outpaces review capacity, we either:
- Slow down PR generation (waste AI’s potential)
- Speed up review (somehow)
- Reduce .NET runtime quality (unacceptable)
Option 2 is the only sustainable path. And it means finding meaningful ways to use AI to assist with code review, not to replace human judgment, but to accelerate the mechanics. Focus the reviewer’s attention, summarize changes, flag patterns, highlight what’s different from standard approaches, identify areas that need closer scrutiny and those that are fine and uninteresting. This is the next frontier: if AI can help write code, it can help validate it, too. CCR is already useful and improving quickly; it catches real issues and helps us spot things we might otherwise miss in a first pass. We’ve also built a custom code-review skill that we can invoke on demand to get a deeper, repo-aware analysis tailored to dotnet/runtime‘s conventions. Where we need the most continued investment is in the bigger picture, helping reviewers focus on what matters most, architectural concerns, subtle cross-cutting consequences, spooky action at a distance, etc., so that human attention is spent where it has the highest impact.
The Power of Instructions
If there’s one insight from this experience worth emphasizing, it’s this: instructions matter enormously. We learned this lesson the hard way, in a very public forum.
The Rocky Start
dotnet/runtime was one of, if not the, first major public repository to adopt CCA. We started using it on the very first day CCA was announced publicly in May 2025. We were excited, eager to experiment, and ready to push the boundaries of what cloud AI-assisted development could accomplish in a production codebase of this scale and complexity.
What we weren’t ready for was the reality of deploying CCA into a codebase like ours without any preparation.
When we first enabled CCA in dotnet/runtime, we had no .github/copilot-instructions.md file. We also weren’t aware of the firewall rules that CCA operates under (by default, the agent runs in a sandboxed environment that blocks access to most external resources). This meant CCA couldn’t download the NuGet packages our build requires. It couldn’t access the feeds where some of our dependencies live. Even if it knew how to build dotnet/runtime (which it didn’t, because we hadn’t told it), it couldn’t actually do it because everything it needed was blocked.
The results were… not great. CCA would submit PRs with code changes, but those changes couldn’t be validated by the agent itself. It was essentially writing code it couldn’t compile, proposing fixes it couldn’t test. Our success rate in May 2025 was 41.7%, more failure than success.
dotnet/runtime is a public open source repo, which meant we were experimenting openly and that our stumbles were visible to everyone. And as it so frequently does, the internet had opinions. Viral threads appeared on Hacker News and Reddit where observers mocked what they saw. Comments compared CCA to incompetent contractors. People made up stories about AI being “forced onto .NET” by mandate. Critics claimed we were pushing AI-generated code directly into the codebase without human oversight. AI skeptics declared this as proof that AI coding was fundamentally broken and should be abandoned.
The criticism reached individual PRs, too. PR #115762, which involved implementing Unicode version retrieval on iOS, became a lightning rod. The PR accumulated over a hundred comments, many hostile, as CCA struggled to get the build working, and external observers piled on in the discussion. The conversation eventually had to be locked.
But here’s what the critics missed or ignored, and what I tried to explain in my comments on that PR:
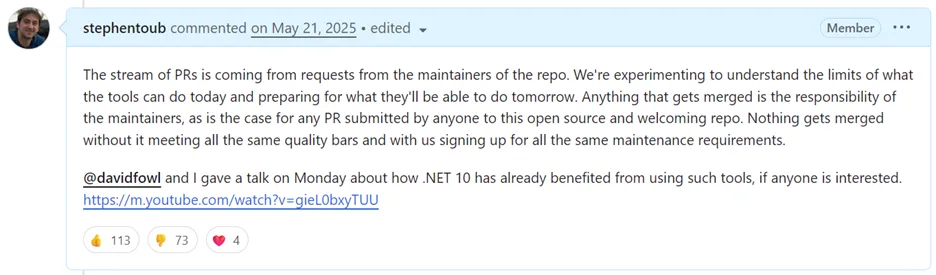
When someone asked if there was a mandate forcing us to use AI:
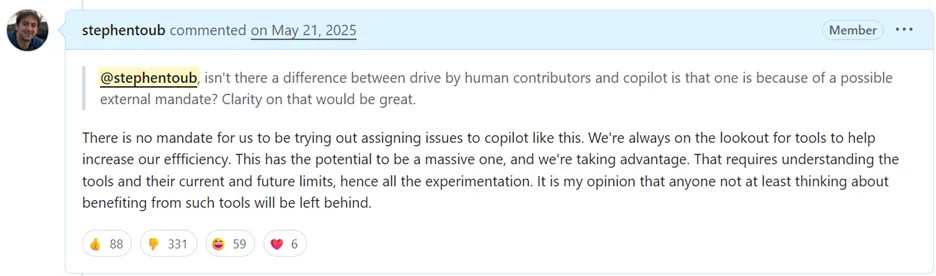
And when people asked why CCA wasn’t building its own code before submitting:
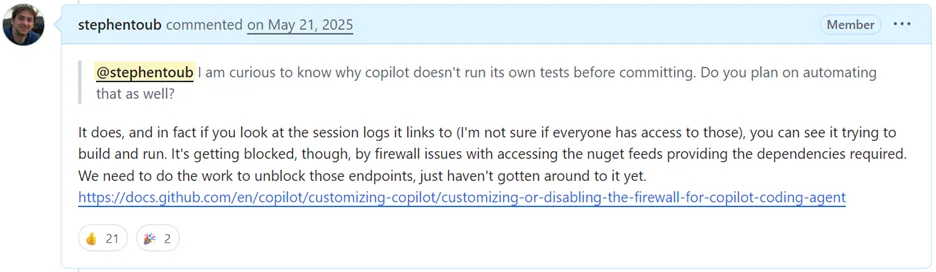
The reality was simple: we’d added a new dev to the team and told them to fix issues without giving them the ability to build or test or download any tools they needed. Any developer, human or AI, would struggle under those constraints. The failure wasn’t in the AI, it was in our preparation.
The Fix
So, we fixed the problems. We configured the firewall rules to allow access to the package feeds our build needs. We created a copilot-instructions.md file explaining how to build the repository, which commands to run in what situations, and what to expect. We added setup steps to get past timeout issues that were happening when CCA tried to build all of dotnet/runtime during its initial processing, a build that can take 20+ minutes even on fast machines.
The correlation was stark:
- PRs created before our first setup changes: 38.1% success rate.
- PRs created after: 69%.
That’s a dramatic improvement, not through better AI models, but through better preparation.
Then we kept iterating. Many commits to our instruction files, each one encoding lessons learned. Here are some of the representative changes:
| Date | Change | Why It Mattered |
|---|---|---|
| May-25 | Created copilot-instructions.md | Gave CCA basic context about the repo structure and build process |
| May-25 | Added dotnet path to setup steps, configured firewall | CCA could finally actually run builds! |
| Jun-25 | Updated build instructions for inner-loop dev | Fewer failed CI runs from incorrect build commands |
| Sep-25 | Added host workflow documentation | Better handling of native code and cross-compilation |
| Oct-25 | Added source generator guidelines | Stopped CCA from making common analyzer/fixer mistakes |
| Nov-25 | Added XML documentation guidelines | Cleaner code style matching our conventions |
| Dec-25 | Split into agent-specific files | More targeted guidance for coding vs review tasks |
| Jan-26 | Tweaked build approach, removed mandatory setup build | Faster iterations for questions/changes that don’t need a full build |
| Feb-26 | Added code review skill based on past PR interactions | CCA code review leverages historical patterns |
| Mar-26 | Updated testing instructions | Clearer guidance on when and how to run tests |
That Jan-26 change is worth explaining. Initially, we had CCA run a full baseline build as part of its setup for every task. This was necessary in our initial usage as CCA would otherwise frequently timeout trying to build the repo during its execution. However, this also meant waiting 20 minutes before CCA could even start looking at whatever triggered it. For quick back-and-forths, asking the agent questions about the codebase, reviewing changes it had made, requesting small tweaks to comments or markdown, that overhead was painful. By January 2026, CCA itself had evolved to the point where these timeouts were no longer a problem, so we adjusted the instructions to encourage CCA to build only when it determined a build was necessary, rather than always upfront. This nicely sped up iteration time, where what was previously always a minimum of a half hour was now minutes.
We’ll continue iterating and fine-tuning. The goal is always faster, more successful interactions.
What goes into good instructions? Here’s what we’ve learned:
Be Specific About Build Commands
dotnet/runtime is a complex repository with complicated build mechanics. We have build.cmd and build.sh with dozens of flags for different scenarios. We have subsets (libs, clr, mono) that build different parts of the repo. We have inner-loop builds that assume you’ve already done a full build at least once. We have architecture-specific requirements and cross-compilation scenarios.
An AI agent dropped into this environment with no guidance will do what any .NET developer would do: try dotnet build and watch it fail. Or try ./build.sh with no arguments and wait 20+ minutes for a full build that might not even be necessary for the task at hand.
Our instructions now explicitly state which commands to run, in what order, and what to expect. Something as simple as “run ./build.sh clr+libs -rc release before making changes to library code” saves countless failed CI runs. We explain when to use inner-loop builds (faster but requires prior full build) versus outer-loop builds (slower but works from a fresh clone). We specify that NativeAOT changes need different build flags than library changes.
This specificity matters because CCA doesn’t have the intuition that comes from months of working in a codebase. If you don’t want it guessing and experimenting (which takes time), you have to tell it.
Document Testing Patterns
Every codebase has testing conventions that aren’t obvious to outsiders, or to AI agents. These conventions often exist for good reasons that aren’t documented anywhere. In dotnet/runtime, we’ve accumulated decades of testing wisdom that we now had to make explicit. For example:
- We don’t assert on exact exception message strings. Why? Because those messages may be localized. A test that passes on an English system might fail on a Japanese system. CCA doesn’t know this unless we tell it, and its instinct is to write precise assertions.
- We use
[ConditionalFact]and[ConditionalTheory]for platform-specific tests. A test that only applies to Windows shouldn’t run on Linux, but xUnit doesn’t know that by default. Our custom attributes handle this, but CCA needs to know when to use them. - Some tests can’t run on .NET Framework, only .NET Core. Our test projects often multi-target, and not all tests are valid on all targets. CCA would write tests assuming modern .NET features that break on older frameworks.
- Inner-loop test runs don’t cover all configurations. CCA might run tests locally and see green, but CI runs tests across dozens of configurations. Success locally doesn’t guarantee success in CI.
After adding explicit testing guidelines that covered these patterns, we saw a marked improvement. Fewer tests had to be deleted or heavily modified during review. CCA was writing tests that actually fit our conventions.
Explain Architectural Boundaries
One of CCA’s recurring mistakes in our early days was using InternalsVisibleTo to expose internal APIs for testing. When the agent needs to test a private method, its instinct was to expose it. That’s a reasonable instinct for throwaway code, but it’s often the wrong choice for a production codebase, especially one that’s in the business of exposing very curated sets of APIs.
In dotnet/runtime, we’re extremely careful about what internals we expose. Every InternalsVisibleTo creates a contract, and we can’t easily change that internal API without breaking tests or other assemblies that depend on it. We’ve had cases where years-old InternalsVisibleTo declarations constrained our refactoring options. InternalsVisibleTo also inhibits various optimization possibilities.
Adding a note to our instructions explicitly discouraging use of InternalsVisibleTo reduced this pattern significantly. Now CCA looks for ways to test through public APIs first, which produces more maintainable tests.
Acknowledge Limitations
Our instructions now explicitly state that the CCA environment runs on Linux. This simple fact has profound implications: Windows-only code can’t be compiled by the agent. macOS-specific tests can’t be run, ARM64 optimizations can’t be verified, etc.
Stating this explicitly in the instructions helped in two ways. First, CCA makes different choices: it might note in its PR description that it couldn’t test the Windows code path and recommend human verification. Second, it sets expectations for reviewers who might otherwise wonder why CCA didn’t test something obvious.
The lesson generalizes beyond platform limitations: every hour spent documenting “how we work” pays dividends across all future AI contributions. It’s not just helpful for CCA, either; it’s helpful for new team members, for external contributors, for your future self who forgot how the build system works. The act of explaining your codebase to an AI forces you to articulate things you might have left implicit for years.
What Works: The Sweet Spots
After 878 PRs, clear patterns have emerged about where CCA excels (at least today; we’ve already seen enhancements to CCA and improvements in the models make a marked improvement in the kinds of tasks CCA can handle.) These aren’t arbitrary categories; they represent real lessons about matching task types to AI capabilities.
| Category | PRs | Success Rate |
|---|---|---|
| Removal/Cleanup | 77 | 84.7% |
| Testing | 99 | 75.6% |
| Refactoring | 86 | 69.7% |
| Bug Fix | 317 | 69.4% |
| Documentation | 52 | 68.1% |
| Update/Upgrade | 44 | 67.4% |
| Feature | 131 | 64.5% |
| Performance | 46 | 54.5% |
| Other | 26 | 11.5% |
The pattern is clear: mechanical tasks with well-defined scope succeed; tasks requiring judgment, exploration, or domain expertise struggle. If you have a good sense of what the change should be (and can describe it), that’s a good indication CCA will do well.
Removal and Cleanup (84.7% Success Rate)
Our highest success rate by category, and it’s not close. When you need to remove deprecated code, delete dead branches, clean up obsolete APIs, CCA is remarkably good at it. The task is well-defined, the scope is clear, and there’s little room for creative interpretation that could lead the agent astray. Unlike when using a local AI agent, CCA largely runs in an unattended mode, where you give it a task and it executes without needing to ask clarifying questions. For mechanical tasks like cleanup, this is ideal. You don’t need to be there to guide it through the process; you just need to give it the right instructions upfront.
Consider PR #120630: replacing Marshal.AllocHGlobal with NativeMemory.Alloc across the codebase. This is exactly the kind of mechanical, tedious work that humans don’t enjoy and often rush through. We’d miss occurrences, make typos, forget edge cases. CCA doesn’t get tired. However, the models today can be a bit lazy, such that sometimes CCA needs to be nudged to look for more occurrences or to do broader searches. For example, PR #122953 required searching for all occurrences of NET9_0_OR_GREATER and NET10_0_OR_GREATER, but for whatever reason CCA ended up constraining its searches to only a portion of the repo, such that a non-trivial number of occurrences remained in tests. I had to explicitly prod it to do a full repo search, at which point it found and fixed the remainder.
Testing (75.6% Success Rate)
Writing tests is one of CCA’s strengths. In the repos where I’m most active, a significant share of new test cases over the last half year have been AI generated.
Adding tests to improve code coverage is a natural fit for CCA. The agent can analyze code, identify untested paths (both via inspection and through use of automated coverage tools), and generate meaningful test cases. But there’s an important caveat: CCA tends toward quantity over quality initially. It generates many tests, some of which are redundant or test implementation details rather than behavior; it doesn’t necessarily know the right things to be validated. Review often involves pruning rather than adding. We tell the agent “add comprehensive tests,” and it interprets “comprehensive” literally, producing tests for every code path including ones that are trivial or already covered by other tests. (More concerning, CCA can produce tests that validate existing incorrect behavior, effectively encoding a bug as the expected result. This is actively harmful: such tests create false confidence and will cause future correct fixes to appear as regressions. Given that 65.7% of CCA’s added lines are test code, this risk demands careful review attention. This is also an area where better prompting can help, giving clear instructions that the agent shouldn’t assume the source-under-test is correct.)
This isn’t necessarily wrong (over-testing is often better than under-testing), but it does mean that test PRs require more review effort than you might expect. We’re essentially editing an over-eager first draft. Specificity and direction in requests to add tests is often just as important and impactful as for product source.
Refactoring (69.7% Success Rate)
Rename operations, moving code between files, updating call sites… these mechanical transformations are CCA territory. The agent doesn’t get tired, doesn’t miss occurrences, doesn’t introduce typos. It treats every occurrence with the same attention, whether it’s the first or the five-hundredth.
Bug Fixes (69.4% Success Rate)
Bug fixes are our bread and butter with CCA. When an issue clearly describes the problem, ideally with a reproduction, expected behavior, and actual behavior, CCA can often implement a fix with tests in a single iteration. The agent reads the issue, traces through the code, identifies where the logic diverges from expectations, and proposes a correction. When a new bug report arrives, I will quickly skim the issue, and if it’s in an area I understand and the issue is actionable, I’ll immediately assign it to CCA.
The key qualifier is “clearly describes.” Vague bug reports produce vague fixes. Issues that say “X doesn’t work” without specifics lead to PRs that might fix a symptom but miss the root cause. We’ve learned to invest time upfront in writing good issue descriptions, even when we’re the ones who will assign that issue to CCA minutes later. That investment pays dividends in the quality of the first attempt.
A great example is PR #123223, which addressed an issue opened by a member of our team describing a corner-case bug he’d encountered: the Base64 and Base64Url types were incorrectly handling small destination buffers when there was whitespace in the input to be decoded, resulting in erroneous “destination is too short” results. The issue included a repro as well as a brief comment that the workhorse method backing these isn’t correctly handling the possibility of skippable whitespace. A few minutes after he opened the issue, I assigned it to CCA. It quickly found where to add the missing if block that would handle the cited corner-case and generated the fix and a few test cases. We left a few comments requesting additional tests, which it added. And then the PR was merged. But, CCA doesn’t extrapolate. It doesn’t go beyond what it was asked to do. It’s not curious, and it doesn’t explore beyond the scope of its assignment. That same developer subsequently realized there were additional variations of the problem, and re-opened the issue and an additional PR: CCA’s original fix was correct (and remained unaltered in the follow-up PR) but didn’t explore or address the larger space.
Specific Library Areas
Some parts of the codebase are more CCA-friendly than others. The managed library areas show strong success rates, particularly when the code follows clear patterns and has good test coverage. System.Text.RegularExpressions has been a particular sweet spot: I’ve been able to assign complex optimizations or bug fixing tasks, and CCA delivers solid implementations that just need polish.
| Area | PRs | Success Rate |
|---|---|---|
| System.Runtime.InteropServices | 11 | 90.0% |
| System.Reflection | 10 | 87.5% |
| System.Net.Http | 17 | 86.7% |
| System.Net | 22 | 84.2% |
| System.Text.RegularExpressions | 23 | 82.6% |
| System.IO | 31 | 75.0% |
| System.Security | 13 | 75.0% |
| System.Text.Json | 28 | 70.6% |
What Struggles: The Challenging Areas
Native Code
Native code has been one of our most challenging areas for CCA. The dotnet/runtime repository contains significant C++ code in CoreCLR. While we’ve had individual successes in these areas, there are fundamental limitations that make CCA less effective here:
CCA runs on Linux only. This is a critical constraint for a codebase like ours. A huge portion of our native code is platform-specific, with separate implementations for Windows, Linux, and macOS, or for different hardware architectures (x64, ARM, WASM). CCA can write code that targets Windows, but it can’t compile or test it. This means Windows-specific changes require humans to verify locally or wait for CI, and when CI fails, someone has to manually relay that failure back to CCA. It considerably increases the back and forth, the number of iterations, the time for each iteration, and thus the overall cost/benefit equation for using CCA in the first place. Note that CCA’s abilities here actually improved last month, but the constraints are such that we’ve still not been able to utilize it in dotnet/runtime. Hopefully soon.
C++ is harder than C#. The agent makes more mistakes in native code: incorrect memory management, misunderstanding ownership semantics, missing platform-specific preprocessor guards. Managed code has more guardrails, with the C# compiler catching more errors; C++ is unforgiving. And due to architectural requirements (e.g. the runtime must avoid dependencies on the C++ standard library), we cannot use most standard C++ features.
Cross-platform code requires cross-platform testing and toolsets. When a change touches code that differs across architectures (x64, ARM64, x86) or operating systems, CCA can only verify one configuration. The rest depends on CI catching issues, and the feedback loop is slow (many failure modes simply aren’t reliably testable in CI, either, e.g. a recent issue that only occurred when the heap size was 10s of GBs in size). Moreover, our code isn’t just cross-platform, it supports different features on Windows and Linux, and it does so with fundamentally different toolsets. How you do something with MSVC may simply not exist in clang.
Architecture woes. We rely on architectural features of hardware and operating systems that are sometimes poorly, if it all, documented. And to achieve highest possible performance, we operate at the absolute limit of the guarantees of the hardware and the toolchain.
The coreclr-specific success rates in the raw data look deceptively high because they’re based on small sample sizes of carefully selected tasks. In practice, we’ve been much more cautious about assigning native code work to CCA.
Beyond native code, even managed code that’s platform-specific poses challenges. With our CCA running on Linux on x64:
- It couldn’t test Windows-specific code paths (Registry access, Windows-specific file handling, COM interop).
- It couldn’t verify macOS or iOS or Android behaviors.
- ARM64-specific optimizations required humans to validate.
We have a lot of platform-specific code in dotnet/runtime, especially in System.Private.CoreLib and the networking stack. When assigning issues in these areas, we either accept that CCA will submit code it can’t fully test (leading to longer iteration cycles with CI), or more typically we avoid assigning such issues to CCA entirely and instead use AI locally.
Performance Work (54.5% Success Rate)
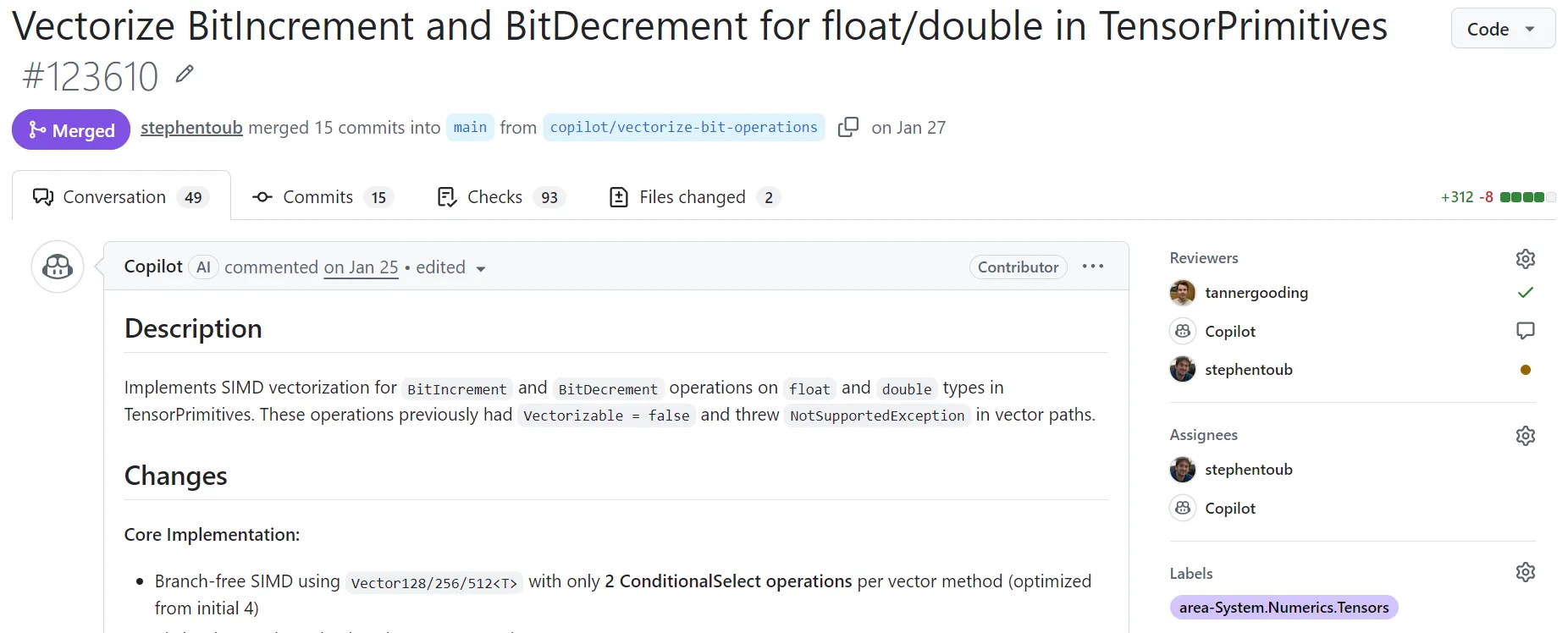
This one hurts me personally, as performance is so dear to my heart. CCA can, for example, implement a complicated SIMD optimization if you tell it exactly what to do, such as in PR #120628 that added Vector512/Vector256 acceleration to UTF-8 utilities and PR #123610 that vectorized more operations on TensorPrimitives:
But it struggles with the analysis part, determining whether a change actually improves performance, understanding the trade-offs, running and interpreting benchmarks.
The agent makes claims like “this improves performance by 2x” without validation. These claims are never trusted at face value; unverified performance assertions in a merged PR would be harmful. We’ve added explicit instructions requiring benchmarks and results, and have a strict policy: no performance PR merges without empirical evidence, regardless of who contributes the PR.
To address this, we created a custom skill (PR #123319) that teaches CCA how to invoke EgorBot, an existing benchmarking bot that can run BenchmarkDotNet benchmarks on dedicated hardware across x64, ARM64, and other configurations. With this skill, the workflow becomes: CCA implements an optimization, writes a benchmark, and invokes EgorBot via a PR comment. When EgorBot finishes, it posts back a comment re-invoking CCA to analyze the results and make any necessary compensations. This is already showing promise. In PR #125280, CCA fixed a regex performance bug, was asked to validate with benchmarks, autonomously invoked EgorBot on both Linux x64 and macOS ARM64, and then analyzed the results (confirming a significant improvement) all without human benchmarking effort. In PR #124320, jkotas asked CCA to validate a Unicode performance optimization; CCA invoked EgorBot, received disappointing results, was asked to analyze why, discovered the approach was flawed, and iterated on a better solution. Even though that particular PR was ultimately closed, the entire investigate-benchmark-analyze loop ran with minimal human involvement.
We’re still early with this skill-based approach, but it represents a key pattern: when CCA lacks a capability, build a skill that bridges the gap rather than accepting the limitation. We now have eight skills in dotnet/runtime, covering performance benchmarking, JIT regression testing, CI failure analysis, API proposal workflows, issue triage, and more. Each one extends what CCA can do autonomously. (We’re also extending this approach beyond dotnet/runtime: the dotnet/skills repository provides reusable skills that any .NET developer can use to enhance their own AI experience, from project upgrades to test generation and beyond.)
Update/Upgrade Work (67.4% Success Rate)
Updating dependencies, bumping versions: these seem mechanical but often involve complex dependency chains, get blocked by code flow between repositories, or are made redundant by other bots bumping versions.
The People Behind the Numbers
Since May 2025, 372 distinct users have submitted PRs to dotnet/runtime. Of those, 70 engineers have invoked CCA to submit at least one PR. Usage is concentrated: the top 10 users account for roughly 58% of all CCA PRs, and the top 2 (me and jkotas) account for ~28%.
An important question is whether CCA’s success generalizes beyond power users or is driven primarily by a few experienced individuals. The data suggests it generalizes well: the top 10 users have a combined success rate of 69.2%, while the remaining 60 users collectively achieve 66.1%. This near-identical performance indicates that CCA effectiveness is not primarily a function of individual expertise with the tool: engineers who assigned just a handful of CCA PRs saw similar outcomes to those who assigned hundreds. Individual success rates do vary widely, from the low 30s to the low 80s, but that variation correlates more with the types of tasks assigned than with the user’s experience level.
For both me and jkotas, CCA has represented a fundamental shift in how coding work is accomplished. Consider how my own contribution patterns have shifted across the repositories where I’m most active:
| Month | stephentoub PRs | stephentoub CCA PRs | Total | CCA % |
|---|---|---|---|---|
| May-25 | 3 | 6 | 9 | 66.7% |
| Jun-25 | 15 | 0 | 15 | 0.0% |
| Jul-25 | 33 | 2 | 35 | 5.7% |
| Aug-25 | 8 | 3 | 11 | 27.3% |
| Sep-25 | 6 | 4 | 10 | 40.0% |
| Oct-25 | 5 | 48 | 53 | 90.6% |
| Nov-25 | 4 | 5 | 9 | 55.6% |
| Dec-25 | 0 | 19 | 19 | 100.0% |
| Jan-26 | 13 | 57 | 70 | 81.4% |
| Feb-26 | 19 | 25 | 44 | 56.8% |
| Mar-26 | 8 | 9 | 17 | 52.9% |
| Month | stephentoub PRs | stephentoub CCA PRs | Total | CCA % |
|---|---|---|---|---|
| May-25 | 2 | 0 | 2 | 0.0% |
| Jun-25 | 12 | 0 | 12 | 0.0% |
| Jul-25 | 19 | 1 | 20 | 5.0% |
| Aug-25 | 7 | 0 | 7 | 0.0% |
| Sep-25 | 21 | 5 | 26 | 19.2% |
| Oct-25 | 19 | 7 | 26 | 26.9% |
| Nov-25 | 13 | 8 | 21 | 38.1% |
| Dec-25 | 5 | 6 | 11 | 54.5% |
| Jan-26 | 3 | 13 | 16 | 81.2% |
| Feb-26 | 8 | 19 | 27 | 70.4% |
| Mar-26 | 8 | 11 | 19 | 57.9% |
modelcontextprotocol/csharp-sdk:
| Month | stephentoub PRs | stephentoub CCA PRs | Total | CCA % |
|---|---|---|---|---|
| May-25 | 4 | 0 | 4 | 0.0% |
| Jun-25 | 12 | 0 | 12 | 0.0% |
| Jul-25 | 4 | 0 | 4 | 0.0% |
| Aug-25 | 2 | 0 | 2 | 0.0% |
| Sep-25 | 1 | 0 | 1 | 0.0% |
| Oct-25 | 9 | 18 | 27 | 66.7% |
| Nov-25 | 5 | 10 | 15 | 66.7% |
| Dec-25 | 1 | 19 | 20 | 95.0% |
| Jan-26 | 4 | 19 | 23 | 82.6% |
| Feb-26 | 6 | 60 | 66 | 90.9% |
| Mar-26 | 1 | 5 | 6 | 83.3% |
The pattern is consistent across all three repositories. In the early months (May-September), I was submitting most PRs to these repos myself: CCA accounted for just 19% of my runtime PRs and 9% of my extensions PRs. Starting in October, that flipped dramatically. Over the most recent six months (October-March), CCA authored 77% of my runtime contributions, 53% of my extensions contributions, and 83% of my MCP SDK contributions. The percentages fluctuate month to month (runtime ranged from 53% to 100%, and the MCP SDK saw three months above 83%), but the overall shift from implementer to reviewer is unmistakable. (December’s 0 personal runtime PRs reflects the holiday period and end-of-year commitments, not an absence of engineering work; PRs don’t capture design reviews, planning, team support, or the many other things that fill a typical month.) It’s worth noting that underlying model improvements over this period contributed to the shift as well; as newer models became available and CCA gained the ability for users to select which model to use, the quality and capability of its output has noticeably improved, making it viable for an increasingly broad set of tasks.
And those non-CCA PRs in the tables above? They’re not purely hand-written code either. Most of my personally-submitted PRs now involve significant AI assistance through Copilot in Visual Studio or Copilot CLI, which I use for everything from generating initial implementations to writing tests to refactoring code to helping to gather and coalesce all the data for this post. The distinction between “personal” and “CCA” PRs understates the actual AI involvement, it’s really a question of whether the AI worked more autonomously (CCA) or more collaboratively in my terminal (Copilot CLI).
This isn’t me doing less work. My total contribution volume across these repositories has actually increased. What’s changed is how I work. Instead of spending hours implementing fixes myself, I spend minutes triaging issues, reviewing CCA’s output, and collaborating with either Copilot CLI or copilot in Visual Studio on the work that needs more direct guidance. The work that remains purely for me (business decisions, design decisions, complex debugging, architectural judgment, cross-team collaboration, helping teammates, 3rd-party engagements, etc.) is higher-leverage work that only a human can do.
That shift, from implementer to reviewer and guide, has meaningfully changed how I work. AI has created capacity to actually do more meaningful work. The backlog shrinks faster. The tedious work gets done. And I can focus on the problems that actually require my expertise (which often ends up being things other than contributing my own PRs). Time that would have been spent on mechanical implementation is now spent on ideation, design, architecture, mentoring, and the kind of deep work that moves the platform forward.
The Autonomy Question
A natural question: how autonomous is CCA really? Can you assign an issue and walk away, or does it require constant hand-holding?
The data tells an interesting story. The average merged CCA PR in dotnet/runtime has 6.9 commits. But raw commit counts can be misleading about how much human guidance was actually needed. Today, CCA always creates an empty initial commit when setting up the branch, and as CCA has evolved, it increasingly produces multiple commits as part of its initial autonomous work, before any human has looked at the PR. A small number of PRs in our data have only a single commit due to force-pushed history rewrites; these 6 PRs are excluded from the commit analysis below but included in all other statistics.
To understand the real iteration story, we can separate each PR’s commits into two phases: the initial autonomous effort (commits before the first human comment) and the post-feedback iteration (commits after a human first engaged). Across all 529 merged CCA PRs with intact commit history:
| Initial Effort | Post-Feedback | Total | |
|---|---|---|---|
| Average commits | 2.7 | 4.1 | 6.9 |
| Median commits | 2 | 2 | 5 |
The median PR starts with just 2 initial commits (the setup commit plus one code commit). CCA’s initial pass is typically a single-shot attempt:
| Initial Commits | PRs | % |
|---|---|---|
| 0-1 | 20 | 3.8% |
| 2 | 328 | 62.0% |
| 3-5 | 165 | 31.2% |
| 6-10 | 9 | 1.7% |
| 11+ | 7 | 1.3% |
62% of merged PRs began with exactly two commits: CCA made one attempt and then the PR waited for feedback. Another 31% made a few self-corrections before submitting. Only 3% involved CCA doing substantial autonomous iteration. The 20 PRs with 0-1 initial commits represent cases where CCA hadn’t yet produced work before a human engaged (e.g. a reviewer commenting on the PR description or the setup commit itself).
After the first human comment, the iteration picture across all 529 PRs:
| Post-Feedback Commits | PRs | % | Interpretation |
|---|---|---|---|
| 0 | 158 | 29.9% | Merged as-is after review |
| 1-3 | 177 | 33.5% | Light iteration |
| 4-10 | 150 | 28.4% | Moderate guidance |
| 11+ | 44 | 8.3% | Significant iteration |
Nearly a third of PRs (29.9%) merged without any post-feedback commits: CCA’s initial effort was accepted as-is. This includes 62 PRs that received no human comments at all, almost all simple two-commit PRs that were approved without discussion. Another 34% needed only light iteration (1-3 additional commits). Altogether, 158 of the 529 analyzed PRs (29.9%) required no iteration beyond CCA’s initial attempt. Of the post-feedback commits across the PRs that did iterate, 1,332 were by CCA (responding to review comments) and 838 were by humans (pushing fixes directly).
A raw “6.9 average commits” might suggest extensive back-and-forth, but the breakdown tells a different story: CCA typically delivers its solution in a single pass, and the subsequent iteration is the same kind of review-and-revise cycle that happens with any contributor. This speaks to the bread-and-butter cases where developers working on dotnet/runtime gravitate towards CCA rather than (or in addition to) using local AI agents. While steering (providing feedback as the agent runs) is possible with CCA, local AI agents excel at situations that benefit from more planning, more interaction, more back-and-forth between the agent and the human, whereas CCA is great for work that’s much more fire-and-forget in nature, that doesn’t have ambiguity that would benefit from human guidance along the way.
Human Intervention
I define “human intervention” here to mean commits pushed directly to a CCA branch by a human developer, not review comments or feedback that CCA then acts on, but actual code changes made by a person. When a fix is faster to implement than to explain, or when CCA needs assistance, humans step in and push commits directly.
Here’s where it gets really interesting. The commit-level authorship analysis below covers all 878 CCA PRs:
| Category | PRs | Merged | Closed | Success Rate |
|---|---|---|---|---|
| With human commits | 396 | 280 | 45 | 86.2% |
| Without human commits | 482 | 255 | 208 | 55.1% |
When humans push commits directly to CCA branches, stepping in to fix something the agent couldn’t or that was faster for the human to “just do”, the success rate jumps to 86%. Without that intervention, it’s 55%. The 55% rate for fully autonomous CCA PRs shouldn’t be viewed in isolation, though; it’s the rate when humans chose not to intervene, and that choice itself is a signal. Many of the closed-without-merge PRs in the “without intervention” bucket were exploratory: we assigned an issue to see what CCA would produce, reviewed the result, and decided the approach wasn’t right, or the change wasn’t needed, or the task was beyond current capabilities, or that we learned everything we needed to from it as a brainstorming phase. That’s a legitimate use of CCA, using it for exploration and prototyping, even if the PR itself doesn’t merge.
This reinforces a crucial insight: CCA is a force multiplier, not a replacement. The 52% of merged PRs that received human commits often needed a specific tweak that was faster to implement directly than to explain to the agent. And that’s okay, the agent still did the bulk of the work.
It’s worth noting that this pattern of human intervention isn’t unique to CCA, just more pronounced. Among the 3,585 merged human-authored PRs in dotnet/runtime during this same period, 368 (10.3%) also received commits from someone other than the original PR author. Maintainers pushing fixes or improvements to other people’s PRs is a normal part of collaborative open source development. The same top contributor appears in both contexts: jkotas pushed commits to 129 human-authored PRs (by other people) and was also the most active reviewer on CCA PRs. Comparing on the same basis, CCA’s 52.3% intervention rate is roughly 5x the human baseline, but the practice itself is familiar, not novel. The difference is one of degree. Beyond direct commits, review comments are themselves a form of collaborative contribution: merged CCA PRs average 16.5 comments vs 12.4 for human PRs, but both populations show that substantive review engagement is the norm, not the exception (only 13% of merged PRs in either population have two or fewer comments).
Human intervention in CCA PRs isn’t the only kind of human intervention. Long before coding agents, we as maintainers of dotnet/runtime intervened in PRs all the time, contributing commits to external and 1st party contributions alike. Many of those interventions are for things that CCA would actually be quite good at, and I expect we would make significantly more use of CCA in dotnet/runtime if we were able to summon it for assistance on PRs it didn’t create. Unfortunately, at the moment, CCA is unable to assist with PRs where the source branch is not in the same repo, which is the case for pretty much every human-authored PR in dotnet/runtime (the PRs come from branches in forks). The day CCA gains that capability will be a huge boon for productivity of dotnet/runtime maintainers.
Code Review
We can look at review comments to get a sense for the interaction required on these PRs.
Across all of the 878 CCA PRs, here are those PRs bucketed by review comment counts on the PRs:
| Number of Comments | Count | Percent |
|---|---|---|
| 0 | 68 | 7.7% |
| 1-2 | 131 | 14.9% |
| 3-5 | 176 | 20.0% |
| 6-10 | 175 | 19.9% |
| 11-20 | 156 | 17.8% |
| 21-50 | 131 | 14.9% |
| 51+ | 41 | 4.7% |
If we then further constrain it to the 535 that were merged:
| Number of Comments | Count | Percent |
|---|---|---|
| 0 | 12 | 2.2% |
| 1-2 | 55 | 10.3% |
| 3-5 | 108 | 20.2% |
| 6-10 | 120 | 22.4% |
| 11-20 | 109 | 20.4% |
| 21-50 | 101 | 18.9% |
| 51+ | 30 | 5.6% |
The average merged PR receives 16.5 total comments (including PR conversation, inline code reviews, and review submissions with text). The distribution shows most merged PRs cluster in the 6-50 comment range (62% of merged PRs), with 6% exceeding 50 comments, indicating extended back-and-forth on complex changes. The lowest-touch merged PRs (1-2 comments, just 10.3% of merges) were typically straightforward fixes that needed only a quick approval. The 12 merged PRs showing zero comments were approved by a reviewer who clicked approve without writing any text… a human reviewed and signed off, just without leaving written feedback. (For comparison, 7.7% of all CCA PRs (including open and closed) have zero comments; these are predominantly PRs that were abandoned quickly or are still awaiting initial review.)
That’s substantial engagement; these aren’t rubber-stamp reviews. In fact, comment counts on CCA PRs are substantially higher than on human PRs. Here’s how comment activity compares across all human-authored and CCA PRs in the ten-month window. Note that these are different populations: CCA PRs skew toward bounded library tasks while human PRs span all areas including complex JIT/GC/runtime work, so the comparison is illustrative rather than controlled:
| Metric | CCA | Human |
|---|---|---|
| Total PRs | 878 | 4,493 |
| Merged | 535 | 3,585 |
| Success Rate | 67.9% | 84.9% |
| Average Comments (merged) | 16.5 | 12.4 |
| Median Comments (merged) | 10 | 7 |
We can also look at the comment distribution on merged PRs:
| Comments | CCA | Human |
|---|---|---|
| 0-4 (quick approval) | 27.1% | 33.6% |
| 5-10 | 28.0% | 33.3% |
| 11-20 | 20.4% | 17.6% |
| 21-50 (heavy iteration) | 18.9% | 11.8% |
| 51+ | 5.6% | 3.7% |
Based on these numbers, the median CCA PR requires 43% more review comments (10 vs 7) than a human PR, and human PRs are more likely to sail through quickly (33.6% vs 27.1% in the 0-4 comment bucket). A measurably larger percentage (24.5% vs 15.5%) of CCA PRs require heavy iteration (21+ comments). However, complex PRs exist in both populations, with ~6% of CCA and ~4% of human PRs exceeding 51 comments.
This highlights that the dotnet/runtime maintainers are genuinely reviewing CCA’s work rather than blindly trusting it. The high comment counts on merged PRs indicate iterative refinement: CCA proposes, humans critique (and sometimes CCR critiques), CCA revises, and so on, rather than one-shot acceptance.
Who’s doing all this reviewing? 284 distinct users commented on the 878 CCA PRs, but the top 10 reviewers account for 61% of all comments (and the top two alone, jkotas and me, account for 36% of all human feedback on CCA PRs). This concentration could be a sustainability concern: if key reviewers burn out, CCA throughput would drop significantly. However, the trend is encouraging: the number of distinct people reviewing CCA PRs has grown organically over time, from 12 in May 2025 to a peak of 80 in February 2026 (58 in March, a partial month at the time of this post). As more engineers assign work to CCA and become comfortable with the workflow, the review base expands naturally.
With all this review and iteration, the median time to merge is ~2 days, while the average is just over a week. The wide gap between median and mean indicates that most PRs merge relatively quickly, but outliers drag the average up substantially.
| Time to Merge | PRs | % |
|---|---|---|
| < 1 hour | 14 | 2.6% |
| 1-4 hours | 21 | 3.9% |
| 4-24 hours | 149 | 27.9% |
| 1-3 days | 124 | 23.2% |
| 3-7 days | 83 | 15.5% |
| 1-2 weeks | 61 | 11.4% |
| 2+ weeks | 83 | 15.5% |
The bulk of PRs (58%) merge within three days. The long tail of 2+ week merges (16%) typically involves complex changes requiring multiple review rounds, changes blocked by external factors, or simply maintainers too busy with other priorities.
All of this activity can happen at all manner of the day or week. Our hourly distribution for PR creation reveals interesting patterns:
| Time Range (UTC) | CCA PR Creation |
|---|---|
| 00:00 – 05:59 | 152 PRs (17.3%) |
| 06:00 – 11:59 | 110 PRs (12.5%) |
| 12:00 – 17:59 | 263 PRs (30.0%) |
| 18:00 – 23:59 | 353 PRs (40.2%) |
The late afternoon/evening peak (UTC) corresponds to standard work hours on the US west and east coasts, when our primary contributors are most active. But there’s significant activity across all hours, including weekends: 144 PRs (16% of all CCA PRs) were created on Saturdays and Sundays, and they merged at comparable rates to weekday PRs. CCA enables asynchronous contribution in a way that wasn’t previously possible. Assign an issue before bed, wake up to a PR ready for review.
We can also get a sense for the nature of all of this feedback. I asked Opus 4.6 to analyze all of the human comments across the 535 merged CCA PRs, asking it to categorize the feedback. (The 16.5 average comments per PR includes all comments: human, CCA responses, and bot messages. The categorization below covers only the human-authored comments. As with any AI-generated categorization, there’s inherent subjectivity in how comments are classified, and an AI model may have systematic biases when evaluating AI-related workflows. The results should be taken as directional rather than precise.)
| Category | Count | % | Description | Example |
|---|---|---|---|---|
| Code suggestions | 2,304 | 45.3% | Specific changes | “This should call the ThrowHelper method instead of manually throwing the exception” |
| General discussion | 1,064 | 20.9% | Meta discussion | “Let me know if you think we should have this fix in a separate PR instead of merging it with this PR” |
| CI commands | 423 | 8.3% | e.g. running additional CI legs | “/azp run runtime-extra-platforms” |
| Clarification questions | 394 | 7.8% | Questions seeking explanation | “Why not just use System.Numerics.Complex?” |
| Fix failures | 233 | 4.6% | Address build/test/CI failures | “timed out. let’s try again while we figure out how to raise the timeout.” |
| Approval | 151 | 3.0% | LGTM, “ship it”, etc. | “LGTM if CI is green” |
| Expand scope / do more | 121 | 2.4% | Also do X | “search whole repo for collectPerfCounters and do rename everywhere. You missed few” |
| Style / nits | 103 | 2.0% | Formatting | “Nit: formatting seems a bit off on the chained calls?” |
| Add tests | 98 | 1.9% | Requesting additional test coverage | “There is no test coverage for the nativeaot change. I would like to see it exercised by tests.” |
| Architectural feedback | 92 | 1.8% | Questioning approach or design | “Should we go with this approach, or rather introduce overloads of the Marshal APIs that take pointers?” |
| Cross-references | 74 | 1.5% | Links to issues | “log issues like: github.com/…/issues/121754” |
| Conflict / rebase | 26 | 0.5% | Merge conflict resolution | “please resolve conflicts” |
The most striking result here: among merged PRs, only 1.8% of comments indicate CCA’s overall approach needed to be revised. The single largest category is specific code suggestions (45%), indicating reviewers are actively steering CCA’s output with concrete changes. The vast majority of feedback is guidance, telling CCA what to do next, not correcting fundamental misunderstandings. This suggests that for the tasks CCA successfully completes, it generally understands the intent of issues; it needs steering more than correction. Of course, there is some selection bias built into this. As we’ve learned what CCA succeeds with and struggles with, we’ve tended away from giving CCA too many open-ended problems, as they’ve had a lower success rate. Moreover, without a good sense for what the solution should be and an understanding of the various available approaches, it’s harder for a reviewer to then correctly evaluate CCA’s outcomes.
Greenfield vs. Brownfield: A Tale of Two Codebases
The contrast between dotnet/runtime and modelcontextprotocol/csharp-sdk is also instructive.
dotnet/runtime is the ultimate brownfield project. Decades of history, millions of lines of code, conventions that evolved organically, platform-specific quirks accumulated over generations of OSes, accommodations made when it grew to be truly cross-platform, evolutions of APIs and API patterns. Every change exists in context, context that CCA must somehow intuit or be taught.
modelcontextprotocol/csharp-sdk started in the spring of 2025 as a greenfield implementation of the Model Context Protocol specification. No legacy, no historical baggage, no “we do it this way because of something that happened in .NET Framework 2.0.”
The numbers tell an interesting story:
| Metric | dotnet/runtime | mcp/csharp-sdk |
|---|---|---|
| Success Rate | 67.9% | 77.3% |
| Average Commits (merged) | 6.9 | 5.2 |
| Human Intervention Rate | 45.1% | 32.6% |
| Median PR Duration (hours) | 50.0 | 17.4 |
| Merged in < 24 hours | 34.4% | 57.4% |
| Average Lines Changed (merged) | 237 | 205 |
| Review comments per 100 lines (all CCA PRs) | 3.73 | 0.37 |
The comparison between dotnet/runtime and modelcontextprotocol/csharp-sdk reveals notable differences in how CCA PRs perform across these codebases:
- MCP demonstrates a higher success rate (77.3% vs 67.9%) and significantly faster time-to-merge, with a median turnaround of just 17.4 hours compared to 50 hours for runtime.
- Interestingly, while merged MCP PRs and runtime PRs average similar lines changed per PR (205 vs 237), MCP PRs merge faster and with less review friction, which makes sense given its greenfield nature.
- The runtime repository requires considerably greater review feedback. Measured across all CCA PRs (merged and unmerged), runtime averages ~3.7 review comments per 100 lines compared to ~0.4 for MCP.
- Despite these differences, both repositories exhibit similar total commit counts, with merged PRs averaging 5-7 commits. As discussed above, a significant share of those commits represent post-feedback iteration rather than CCA’s initial attempt: 60% in dotnet/runtime, 37% in MCP. The lower post-feedback ratio in MCP is consistent with its smaller, more self-contained codebase requiring less back-and-forth (note that some of the same engineers are involved in both repositories).
Of course, these differences aren’t purely a function of greenfield vs. brownfield; the size and complexity of the codebase play a significant role, though to some extent those are all interwined. dotnet/runtime spans millions of lines with decades of accumulated conventions, platform-specific quirks, documented and undocumented behaviors, all of which increase the likelihood of CCA stumbling. A smaller, more self-contained codebase like modelcontextprotocol/csharp-sdk gives the agent less to navigate and fewer places to go wrong. Many of the changes in modelcontextprotocol/csharp-sdk are also implementing a specification, which removes much of the ambiguity CCA could struggle with on less-well-specified work items.
The Laziness Problem
CCA can be lazy. Not in the anthropomorphic sense of lacking motivation, but in the engineering sense of doing the minimum to satisfy a request without considering the broader context.
Examples abound…
Coverage expansion: When asked to improve code coverage, CCA has done the minimum asked for and then stopped. PR #120640, which aimed to improve System.Security.Cryptography.Xml coverage, became a case study in persistence. The conversation went something like this:
- “Please run code coverage, analyze gaps, and add tests to get coverage as close to 100% as possible.”
- CCA added some tests. Coverage: 71.8%.
- “This still needs much better coverage.”
- CCA added more tests. Coverage: 74.7%.
- “Keep going until you reach 90%.”
- CCA added more tests, then stopped. Coverage: 74.9%.
- “Please continue.”
- Coverage: 74.9%.
- “Can you focus on error paths?”
- Coverage: 75.1%.
Performance work: CCA will make the explicit changes mentioned in an issue but not extend the pattern to similar code. “Add Vector256 acceleration to this function” gets done; “and apply the same pattern to all the other relevant functions in this file” requires separate prompting.
Following up on feedback: CCA addresses the specific point raised but doesn’t extrapolate. If a reviewer says “don’t use InternalsVisibleTo,” the agent might remove it from that file but leave identical usages in other files it touched.
In our experience, CCA today optimizes for the immediate request and does not try to infer or intuit a broader goal. That’s a desirable trait in some circumstances and frustrating in others. As users, we’ve learned to:
- Be comprehensive in initial prompts: Don’t say “Add tests.” Say “Add tests for all untested code paths in this type. Use a code coverage tool to determine whether code is tested; do not just use code inspection.”
- Be very clear about boundaries: When you ask a teammate to “avoid using InternalsVisibleTo” here, they may very likely know from past experience with you that you really want them to extrapolate and apply the same pattern elsewhere. CCA doesn’t know anything about you or your preferences (unless you’ve separately encoded those into instructions it always consumes). Tell it exactly what you want it to do. Exactly. (Unless you actually want it to creatively interpret your request.)
- Iterate explicitly: Accept that you’ll need to push back multiple times. Build that expectation into your workflow and planning.
- Watch for patterns: When CCA follows a certain approach in one place, and you don’t like the approach, check if it did the same thing elsewhere.
When “Closed” Is Actually Success
Our headline success rate of 67.9% counts merged PRs as success and closed PRs as failure. But this oversimplifies reality.
Consider these example PRs:
PR #122749: Prototyping
.NET provides the SearchValues<T> type, which enables highly-optimized searching for preconfigured values. Creating a SearchValues<T> allows the implementation to select an optimal strategy based on the exact values being searched for, and there are dozens of optimized strategies available. Issue #91795 proposed another strategy to consider as an optimization for certain kinds of string inputs.
I assigned the issue to copilot, and it did a great job authoring the hundreds of lines of code to implement and test that strategy. As it turned out, however, performance testing the suggestion revealed it wasn’t a desirable addition, and both the PR and issue were closed.
In our metrics, that counts as failure. In reality, however, CCA saved hours of developer time by prototyping a solution and getting it to a point where the experiment could be validated. Had this been on a human’s plate, the human would have (should have) done all this same work, including the performance validation, and may never have opened a PR in the first place.
PR #120871 and PR #121035: Already Addressed
Sometimes issues linger in the backlog after they’ve been incidentally fixed by other changes. CCA occasionally discovers this: it investigates an issue, finds that the behavior is already correct, and submits a PR that essentially says “this is already working, here are tests to prove it.”
These PRs often get closed (we don’t need to merge a PR that adds tests for already-working behavior if the tests already exist elsewhere). But the investigation was valuable.
PR #115826: The Design Exploration
This PR attempted to make HttpClientFactory implement IDisposable. After 55 commits and 81 review comments, it was closed, not because the implementation was wrong, but because the design discussion revealed that the feature wasn’t desirable.
Failure? The conversation happened, the design space was explored, and we made an informed decision not to proceed. That’s engineering.
Systematic Categorization of Closed PRs
To move beyond anecdotes, I had Opus 4.6 categorize all 253 closed CCA PRs by the reason they were closed.
| Category | Count | % of Closed |
|---|---|---|
| Auto-closed draft / abandoned | 112 | 44% |
| Wrong approach | 41 | 16% |
| Superseded by another PR | 32 | 13% |
| Design rejected | 20 | 8% |
| Valuable exploration | 20 | 8% |
| Too complex for CCA | 10 | 4% |
| CI / infrastructure issues | 7 | 3% |
| Already addressed | 6 | 2% |
| Duplicate | 5 | 2% |
The largest category, auto-closed drafts (44%), represents PRs where CCA produced work but no one reviewed it within the repository’s 30-day inactivity window. These are backlog management failures, not CCA failures: the work was requested, CCA delivered something, and it expired unreviewed. This pattern is spread across the entire ten months, not concentrated in the early experimental period.
Only 41 PRs (16%) represent genuinely wrong approaches where CCA’s solution was technically incorrect or unsalvageable. That’s 41 out of 788 resolved PRs (5%).
The valuable exploration (20) and design rejected (20) categories both delivered real value despite not merging. Valuable explorations included prototyping feasibility investigations, and design rejections represented cases like the examples above where the design discussion itself was the product.
If we count merged PRs plus valuable closures (exploration, design discussion, and already-addressed issues where CCA produced a valid fix that was simply no longer needed), the “value delivery” rate rises from 67.9% to 73.7% (581 of 788 resolved PRs). And if we further exclude closures that weren’t CCA’s fault (auto-closed drafts, CI issues, and duplicates), only 83 of the 658 remaining PRs (13%) were closed due to a genuine problem with CCA’s output (wrong approach, superseded by a better solution, iteration time exceeded CCA’s allowed limits making it too complex for CCA, etc.).
Don’t judge CCA solely by merge rate. A PR that teaches you something, even if it doesn’t merge, is a PR that delivered value.
This points to an important use case: CCA as a low-cost exploration tool. Because AI attempts don’t require significant human time upfront, the bar for “worth trying” drops precipitously, and with the scale of the cloud, it’s easy to fire off agents to explore things ad hoc:
- Validating feasibility: Quickly prototype whether an approach is viable.
- Revealing hidden complexity: Expose design issues that weren’t apparent in the issue description.
- Generating discussion: Provide concrete code to react to rather than abstract discussions.
- Low-cost experimentation: Try approaches that might not justify human developer time.
Lessons for Individual Contributors
If you’re an engineer considering CCA or another cloud-based AI coding agent for your codebase, here’s learnings that would have benefited us from the start:
Think of CCA as a Pair Programming Partner, Not a Replacement
The most productive mental model is pairing. You’re the senior developer; CCA is an enthusiastic and talented intern with infinite patience, incredible speed, and questionable judgment. You provide direction, context, and quality control. CCA provides implementation bandwidth.
(One of the CCA users on our team prefers not to anthropomorphize here and instead categorized it this way: “I think of it like adjusting a river. I can’t make it do exactly what I want, but if I put the right blocks and channels in place, I can direct the flow to where it’s most useful and away from where it’s harmful.”)
Match Tasks to AI Strengths
Not every issue is a CCA issue (a local AI agent may be better suited). Good CCA issues:
- Have clear, unambiguous descriptions.
- Specify expected behavior, ideally with a repro.
- Have existing test patterns to follow.
- Don’t require deep architectural decisions that would benefit from planning and iterative human collaboration.
- Don’t touch platform-specific code on platforms CCA can’t test.
- Don’t require subjective judgment about design (“make this API more ergonomic”).
Iteration Is Expected
If you expect CCA to get it right the first time with zero human involvement, you’ll be disappointed a non-trivial percentage of the time. Expect multiple rounds of review feedback with you providing clear, specific, and actionable feedback.
Watch for Laziness
When CCA does the minimum, push it to do more. “Now search for all other occurrences of this pattern across all *.cs files in the whole repo and apply this same solution to each occurrence.” The agent likely won’t extrapolate unless you ask.
Instructions Are Your Lever
Every lesson you encode in .github/copilot-instructions.md is a lesson you don’t have to teach again. When you catch CCA making what you consider to be a mistake, consider: could an instruction have prevented this? If so, update the file, or better yet, have CCA do it as part of the same PR (you can even add an instruction that tells CCA to proactively suggest updates to the instructions file whenever it learns something new about the project during a task; that way, every completed PR becomes an opportunity to make the next one better).
Common things to document:
- Build commands and prerequisites.
- Testing conventions and tools.
- Code style preferences.
- Patterns to avoid.
- Platform-specific considerations.
Exploration Has Value
A closed PR isn’t necessarily a failure. Sometimes the valuable output is learning that a change shouldn’t be made, or that an issue is already fixed, or that a design approach doesn’t work. Measure value, not just merge rate.
Models Keep Getting Better
What struggles today may succeed tomorrow. We’ve seen meaningful improvement in CCA’s capabilities over the months we’ve used it. Tasks that failed in May are succeeding now. Keep experimenting with the boundaries.
Ten Months, 878 PRs, One Takeaway
If there’s one lesson from this experience, it’s this: preparation matters more than the model.
Our success rate jumped from 38% before our instruction file to 69% after. Better preparation was the primary driver. Every hour spent documenting “how we work” in .github/copilot-instructions.md and teaching new skills pays dividends across every future CCA PR. Instructions aren’t just documentation; they’re leverage. They’re the difference between a junior developer who needs constant hand-holding and one who can work semi-autonomously.
Equally important is what you assign. Our category data shows success rates ranging from 85% (removal/cleanup) to 55% (performance), a 30-point spread driven entirely by task selection. The more detailed the issue, the more specific the task prompt, the better CCA does.
We’re still relatively early on this journey, yet CCA is already a meaningful part of how we work: it handles tedious work, explores issues, writes tests, fixes well-reported bugs, and accelerates the long tail of backlog items that would otherwise wait indefinitely. Model upgrades over the past ten months have brought noticeable improvements in code quality and task completion, and we expect that to continue. We’ll keep pushing on using it more, getting better with it, and adapting our workflows accordingly.
Thanks to everyone who continues to push the boundaries and contributes to making .NET better and better, one pull request at a time.
The post Ten Months with Copilot Coding Agent in dotnet/runtime appeared first on .NET Blog.