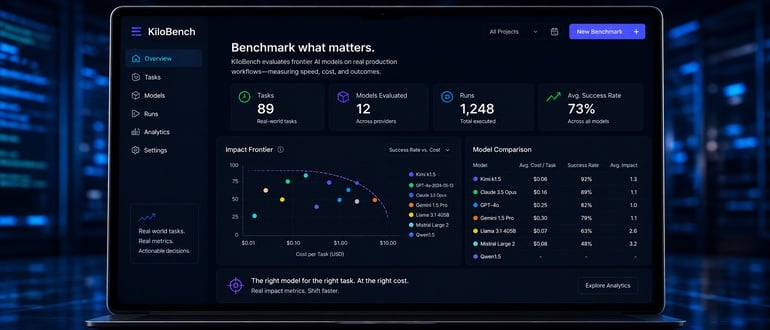
Kilo today made available a benchmarking framework for its open source artificial intelligence (AI) agent that enables application development teams to generate code using multiple models.
Company CEO Scott Breitenother said KiloBench measures the impact that frontier AI models are having on actual production workflows versus relying on a set of benchmarks, such as SWE-bench Verified, that only evaluate AI models based on how well they perform a generic set of tasks.
The KiloBench framework, in contrast, provides deeper insights into workflows that make it possible to determine which AI model lends itself best to a specific harness in terms of how quickly tasks are completed and at what cost, noted Breitenother.
For example, some AI models are able to successfully complete a task on their first try, while others require three attempts. A model that’s cheaper per attempt but needs five tries is more expensive than a model that costs more per attempt but consumes fewer tokens, added Breitenother.
In other cases, it may simply be less expensive to invoke an open source AI model that has been deployed on the same cloud service alongside proprietary AI models from, for example, OpenAI and Anthropic. Too many organizations are making a strategic mistake by adopting harnesses that are too closely coupled with the provider of an AI model, noted Breitenother.
Application developers also need to be aware that not all AI models work the same way. Some models read extensively before writing, which makes it possible to discover more bugs while consuming additional tokens.
KiloBench is based on a Terminal-Bench framework that tracks 89 real-world tasks as they are completed using the Kilo harness. That approach provides more granular insights into which AI models are best optimized for the Kilo AI coding tool, said Breitenother. Ultimately, the goal will be to automatically route tasks based on a set of policies defined by the DevOps team, he added.
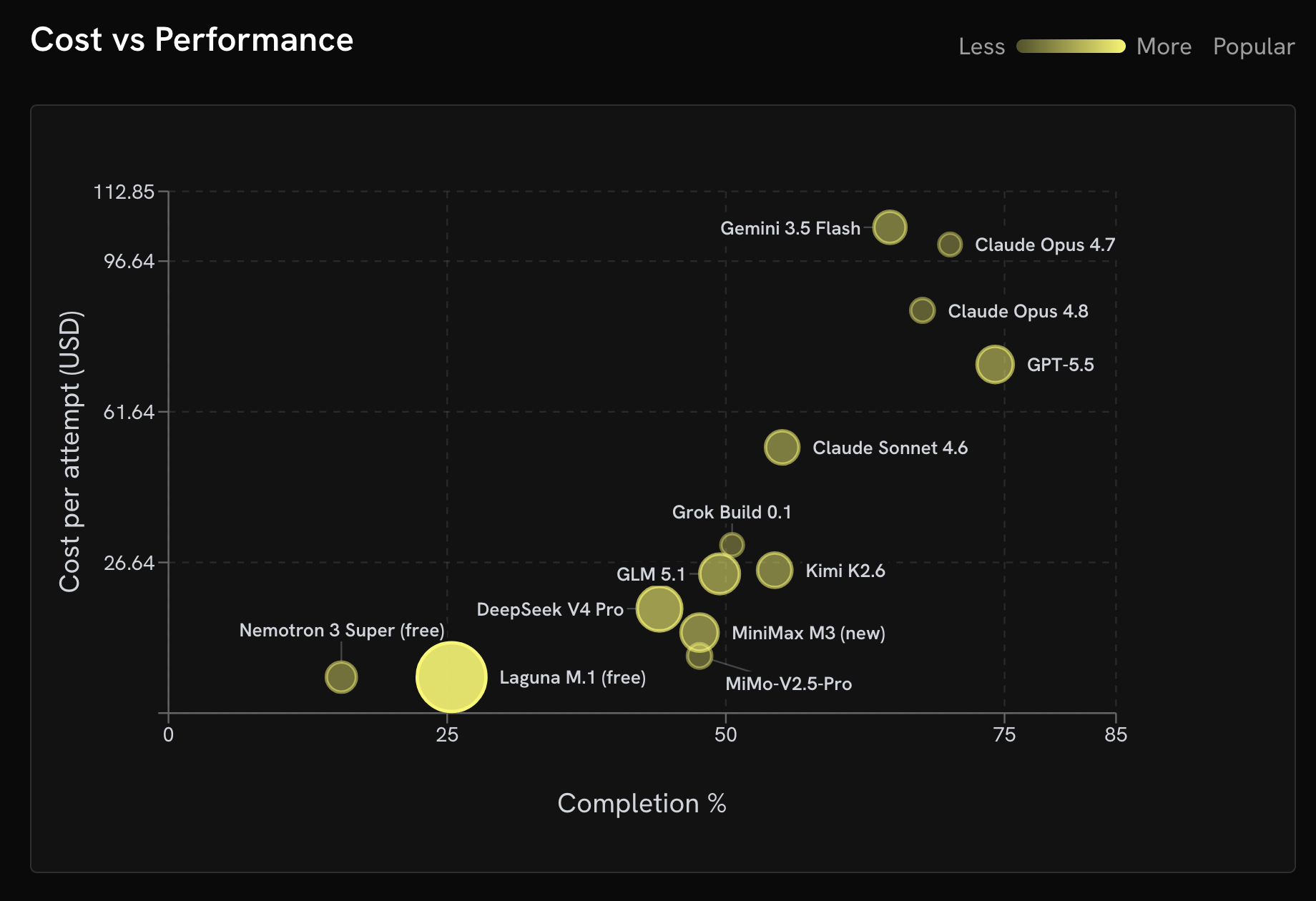
Exactly how each harness interfaces with AI models is slightly different, so in time there is likely to be a greater need for benchmarks that are tied to specific AI coding tools. Having access to those insights is becoming increasingly critical as DevOps teams discover that the cost of the token used to build and deploy software in many instances has become prohibitive.
One way to control those costs is to have a better understanding of which AI models might best be used to perform a specific task. Rather than focusing on how many tokens are consumed, also known as token maxing, DevOps teams will increasingly need to apply best FinOps practices to consumption of AI infrastructure resources, noted Breitenother. Otherwise, more organizations will discover that application developers are regularly running out of allotted tokens that will need to be replenished, he added.
It’s still early days so far as adoption of AI coding is concerned. Most organizations are now using multiple AI tools to generate code but few have defined a set of governance policies and frameworks to optimize usage. The one thing that is certain is that it is now more a question of when rather than if those frameworks and policies will be applied.